Golang笔记
Golang相关配置
golang 配置goproxy可选的地址
IDEA/Goland使用WSL作为默认Terminal
GoLand 2022.1-X专业版激活
Win下用WSL作为Goland终端交叉编译
MacOS下在Goland的Terminal中使用‘ll’命令无效
GoLand 2024.1.X专业版激活
Golang LeeCode练习题
一 Golang数组问题
28. [简单] 寻找数组的中心下标
27. [简单] 数组的度
26. [简单] 最长连续递增序列
25. [简单] 非递减数列
24. [简单] 图片平滑器
23. [简单] 子数组最大平均数 I
22. [简单] 重塑矩阵
21. [简单] 数组拆分 I
20. [简单] 最大连续1的个数
19. [简单] 找到所有数组中消失的数字
18. [简单] 移动零
17. [简单] 丢失的数字
16. [简单] 汇总区间
15. [简单] 存在重复元素 II
14. [简单] 存在重复元素
13. [简单] 多数元素
12. [简单] 两数之和 II
11. [简单] 买卖股票的最佳时机 II
10. [简单] 买卖股票的最佳时机
09. [简单] 杨辉三角 II
08. [简单] 杨辉三角
07. [简单] 合并两个有序数组
06. [简单] 加一
05. [简单] 最大子序和
04. [简单] 搜索插入位置
03. [简单] 移除元素
02. [简单] 删除有序数组中的重复项
01. [简单] 两数之和
29. [简单] 至少是其他数字两倍的最大数
30. [简单] 托普利茨矩阵
31. [简单] 较大分组的位置
32. [简单] 转置矩阵
33. [简单] 公平的糖果棒交换
34. [简单] 单调数列
35. [简单] 按奇偶排序数组
36. [简单] 卡牌分组
37. [中等] 盛最多水的容器
38. [中等] 三数之和
39. [中等] 最接近的三数之和
40. [中等] 四数之和
41. [中等] 下一个排列
42. [中等] 搜索旋转排序数组
43. [中等] 在排序数组中查找元素的第一个和最后一个位置
44. [中等] 组合总和
45. [中等] 旋转图像
Golang完整学习记录
第一章 Go语言简介
20220519@基础环境
20220518@概述
第二章 Go语言基本语法
20220520@基础语法
20220521@正弦函数
20220523@数据类型转换
20220523@指针概念
20220524@堆栈和逃逸分析
20220526@(模拟)枚举
20220528@类型别名
20220528@注释的使用
20220528@关键字与标识符
20220528@运算符的优先级
20220528@数据类型的转换
第三章 Go语言容器
20220531@容器概念
20220531@数组详解
20220531@多维数组
20220605@切片详解
20220606@append的常见操作
20220606@切片元素修改
20220609@多维切片简述
20220609@map映射
20220612@并发(sync)Map
20220614@list(列表)
20220614@nil值/空值/零值
20220615@new和make
第四章 Go语言控制流程
20220615@if分支结构
20220615@for循环
20220615@range遍历
20220615@switch
20220616@goto标签
20220616@break和continue
20220616@聊天机器人
20220620@词频统计
20220622@缩进排序
20220622@二分查找算法
20220622@冒泡排序
20220623@分布式id生成器
第五章 Go语言函数
20220623@函数声明
20220623@函数参数传递效果
20220627@字符串的链式处理
20220630@匿名函数
20220704@函数类型接口
20220704@闭包(Closure)
20220706@可变参数
20220706@defer延迟语句
20220709@递归函数
20220713@处理运行错误
20220714@宕机(panic)
20220714@宕机恢复(recover)
20220715@计算函数耗时
20220718@内存缓存提升性能
20220718@哈希函数
20220720@Test功能测试
第六章 Go语言结构体
20220726@结构体定义
20220726@为结构体分配内存
20220730@实例化结构体
20220803@初始化结构体成员变量
20220810@构造函数
20220816@方法和接收器
20220816@为基本类型添加方法
20220816@使用事件系统实现事件响应和处理
20220817@类型内嵌和结构体内嵌
20220817@结构体内嵌模拟类的继承
20220817@初始化内嵌结构体
20220818@内嵌结构体成员名字冲突
20220823@使用匿名结构体解析JSON数据
20220827@垃圾回收和SetFinalizer
20220828@结构体数据保存为JSON格式
20220901@链表操作
20220908@数据I/O对象及操作
第七章 Go语言接口
20220911@接口定义
20220915@实现接口的条件
20220918@类型与接口的关系
20220918@接口的nil判断
20020918@类型断言简述
20220929@多输出实现日志系统
20221009@排序(by sort.Interface)
20221106@接口的嵌套组合
20221107@接口和类型之间的转换
20221109@空接口类型(interface{})
20221107@空接口实现任意值的字典保存
20221112@switch类型分支
20221201@Error接口返回错误信息
20221229@表达式求值器
20221229@实现Web服务器
20221229@部署Go程序到Linux
20221229@音乐播放器
20221230@有限状态机(FSM)
20221230@二叉树数据结构的应用
第八章 Go语言包概念
20230206@包的基本概念
20230212@封装简介及实现细节
20220212@GOPATH详解
20230212@常用内置包简介
20230212@自定义包
20230212@package(创建包)
20230212@import导入包
20230213@工厂模式自动注册
20230213@单例模式
20230214@sync包与锁
20230215@big包实现整数的高精度计算
20230215@使用图像包制作GIF动画
20230216@正则regexp包
20230218@time包:时间和日期
20230219@go mod包依赖管理工具
20230219@os包用法简述
20230219@flag包:命令行参数解析
20230219@生成二维码
20230219@Context(上下文)
20230220@示例:客户信息管理系统
20230221@发送电子邮件
20230222@Pingo插件化开发
20230221@定时器实现原理及作用
第九章 Go语言并发
20230224@并发简述(并发的优势)
20230224@goroutine(轻量级线程)
202300226@并发通信channe简介
20230226@竞争状态简述
20230227@GOMAXPROCS(并发运行性能)
20230227@并发和并行的区别
20230227@goroutine和coroutine的区别
20230227@通道(channel)—goroutine之间通信的管道
20230227@并发打印(借助通道实现)
20230227@单向通道——通道中的单行道
20230301@无缓冲的通道
20230301@带缓冲的通道
20230302@channel超时机制
20230302@通道的多路复用
20230302@RPC(模拟远程过程调用)
20230304@使用通道响应计时器的事件
20230306@关闭通道后继续使用通道
20230306@多核并行化
20230306@Telnet回音服务器-TCP服务器的基本结构
20230307@竞态检测——检测代码在并发环境下可能出现的问题
20230310@互斥锁(sync.Mutex)和读写互斥锁(sync.RWMutex)
20230310@等待组(sync.WaitGroup)
20230310@死锁、活锁和饥饿概述
20230311@封装qsort快速排序函数
20230311@CSP:并发通信顺序进程简述
20230312@聊天服务器
20230313@如何更加高效的使用并发
20230313@使用select切换协程
20230313@加密通信
第十章 Go语言反射
20230317@反射(reflection)简述
20230318@反射规则浅析
20230319@反射的性能和灵活性测试
20230322@通过反射获取类型信息(reflect.TypeOf()和reflect.Type)
20230325@通过反射获取指针指向的元素类型(reflect.Elem())
20230325@通过反射获取结构体的成员类型
20230325@结构体标签(Struct Tag)
20230325@通过反射获取值信息(reflect.ValueOf()和reflect.Value)
20230326@通过反射访问结构体成员的值
20230326@判断反射值的空和有效性(IsNil()和IsValid())
20230327@通过反射修改变量的值
20230327@通过类型信息创建实例
20230327@通过反射调用函数
20230327@依赖注入(inject库)
第十一章 文件处理
20230327@自定义数据文件
20230328@JSON文件的读写操作
20230402@XML文件的读写操作
20230402@使用Gob传输数据
20230404@纯文本文件的读写操作
20230405@二进制文件的读写操作
20230405@自定义二进制文件的读写操作
20230405@zip归档文件的读写操作
20230405@tar归档文件的读写操作
20230408@使用buffer读写文件
20230409@实现Unix中du命令统计文件
20230410@从INI文件中读取配置
20240411@文件的读写追加和复制
202304111@文件锁操作
第十二章 Go语言编译与工具
20230411@go build命令使用
20230413@clean命令-清除编译文件
20230413@run命令-编译并运行
20230413@fmt命令-格式化代码文件
20230413@install命令-编译并安装
20230414@go get命令-获取代码编译并安装
20230414@go generate命令-在编译前自动生成某类代码
20230415@go test命令-单元和性能测试
20230415@go pprof-性能分析命令
20230415@Go语言与C/C++进行交互
20230415@Go语言内存管理简述
20230415@Go语言垃圾回收
20230415@Go语言实现RSA和AES加解密
Golang简单实战
Golang根据书籍ISBN爬取豆瓣评分和评论数
Go编写使用指定的CPU百分比消耗CPU资源
Golang的日常应用
使用 FFmpeg 进行实时码率检测
WSL的远程开发应用
WSL2设置静态IP
在WSL2中启动SSH
使用CentOS7作为Goland终端的修改项
Golang学习路线
Go开发者成长路线图
本文档使用 MrDoc 发布
-
+
首页
20220901@链表操作
## 链表的特点 >用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的) 链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。 链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 使用链表结构可以避免在使用数组时需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。 链表允许插入和移除表上任意位置上的结点,但是不允许随机存取。链表有三种类型: - 单向链表 - 双向链表 - 循环链表 ## 单向链表 单向链表中每个结点包含两部分,分别是数据域和指针域,上一个结点的指针指向下一结点,依次相连,形成链表。 这里介绍三个概念:首元结点、头结点和头指针。 1. 首元结点:就是链表中存储第一个元素的结点,如下图中 a1 的位置。 2. 头结点:它是在首元结点之前附设的一个结点,其指针域指向首元结点。头结点的数据域可以存储链表的长度或者其它的信息,也可以为空不存储任何信息。 3. 头指针:它是指向链表中第一个结点的指针。若链表中有头结点,则头指针指向头结点;若链表中没有头结点,则头指针指向首元结点。 图:单向链表 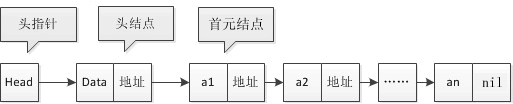 头结点在链表中不是必须的,但增加头结点有以下几点好处: - 增加了头结点后,首元结点的地址保存在头结点的指针域中,对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理。 - 增加头结点后,无论链表是否为空,头指针都是指向头结点的非空指针,若链表为空的话,那么头结点的指针域为空。 ## 使用 Struct 定义单链表 利用 Struct 可以包容多种数据类型的特性,使用它作为链表的结点是最合适不过了。一个结构体内可以包含若干成员,这些成员可以是基本类型、自定义类型、数组类型,也可以是指针类型。这里可以使用指针类型成员来存放下一个结点的地址。 【示例 1】使用 Struct 定义一个单向链表。 ```go type Node struct { Data int Next *node } ``` 其中成员 Data 用来存放结点中的有用数据,Next 是指针类型的成员,它指向 Node struct 类型数据,也就是下一个结点的数据类型。 【示例 2】为链表赋值,并遍历链表中的每个结点。 ```go package main import "fmt" type Node struct { data int next *Node } func Shownode(p *Node) { //遍历 for p != nil { fmt.Println(*p) p = p.next //移动指针 } } func main() { var head = new(Node) head.data = 1 var node1 = new(Node) node1.data = 2 head.next = node1 var node2 = new(Node) node2.data = 3 node1.next = node2 Shownode(head) } ``` 运行结果如下: ``` {1 0xc00004c1e0} {2 0xc00004c1f0} {3 <nil>} ``` ## 插入结点 单链表的结点插入方法一般使用头插法或者尾插法。 ### 1) 头插法 每次插入在链表的头部插入结点,代码如下所示: ```go package main import "fmt" type Node struct { data int next *Node } func Shownode(p *Node){ //遍历 for p != nil{ fmt.Println(*p) p=p.next //移动指针 } } func main() { var head = new(Node) head.data = 0 var tail *Node tail = head //tail用于记录头结点的地址,刚开始tail的的指针指向头结点 for i :=1 ;i<10;i++{ var node = Node{data:i} node.next = tail //将新插入的node的next指向头结点 tail = &node //重新赋值头结点 } Shownode(tail) //遍历结果 } ``` 运行结果如下: ``` {9 0xc000036270} {8 0xc000036260} {7 0xc000036250} {6 0xc000036240} {5 0xc000036230} {4 0xc000036220} {3 0xc000036210} {2 0xc000036200} {1 0xc0000361f0} {0 <nil>} ``` ### 2) 尾插法 每次插入结点在尾部,这也是我们较为习惯的方法。 ```go package main import "fmt" type Node struct { data int next *Node } func Shownode(p *Node){ //遍历 for p != nil{ fmt.Println(*p) p=p.next //移动指针 } } func main() { var head = new(Node) head.data = 0 var tail *Node tail = head //tail用于记录最末尾的结点的地址,刚开始tail的的指针指向头结点 for i :=1 ;i<10;i++{ var node = Node{data:i} (*tail).next = &node tail = &node } Shownode(head) //遍历结果 } ``` 运行结果如下: ``` {0 0xc0000361f0} {1 0xc000036200} {2 0xc000036210} {3 0xc000036220} {4 0xc000036230} {5 0xc000036240} {6 0xc000036250} {7 0xc000036260} {8 0xc000036270} {9 <nil>} ``` 在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以速度较慢。而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的。 但是,有利就有弊。链表要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。 ## 循环链表 循环链表是一种特殊的单链表。 循环链表跟单链表唯一的区别就在尾结点。单向链表的尾结点指针指向空地址,表示这就是最后的结点了,而循环链表的尾结点指针是指向链表的头结点,它像一个环一样首尾相连,所以叫作“循环”链表,如下图所示。 图:循环链表 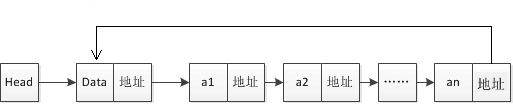 和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题,尽管用单链表也可以实现,但是用循环链表实现的话,代码就会简洁很多。 ## 双向链表 单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。 图:双向链表  双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
Nathan
2022年9月1日 14:14
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码