Prometheus
一、基础简介
1.1.prometheus简介
1.2.数据模型
1.3.指标类型
1.4.Jobs和Instances
二、安装部署
2.1.rpm部署监控组件
2.2.docker部署监控组件
三、PromSQL
3.1.PromQL基本使用
3.2.Prometheus基础查询
3.3.查询操作符
3.4.内置函数
3.5.在HTTPAPI中使用PromQL
3.6.最佳实践
四、告警处理
4.1.告警简介
4.2.自定义Prometheus告警规则
4.3.常见告警规则
4.4.部署Alertmanager
4.5.Alertmanager配置概述
4.6.基于标签的告警处理路由
4.7.使用Receiver接收告警信息
4.8.自定义告警模板
4.9.屏蔽告警通知
4.10.使用RecodingRules优化性能
五、Exporter
5.1.exporter
5.2.NodeExporter
5.3.ProcessExporter
5.4.cAdvisor
5.5.MysqlExporter
5.6.BlackboxExporter
5.7.ProcessExporter
5.8.Ipmiexport
5.9.Pushgateway
PostgresExporter
六、Grafana
6.1.grafana基本概念
6.2.创建dashboard与Panel
6.3.变化趋势:Graph面板
6.4.graph面板常用操作
6.5.分布统计:Heatmap面板
6.6.当前状态:SingleStat面板
6.7.变量
6.8.grafana报警
七、集群高可用
7.1.本地存储
7.2.远程存储
7.3.联邦集群
7.4.prometheus高可用
7.5.Alertmanager高可用
八、服务发现
8.1.Prometheus与服务发现
8.2.基于文件的服务发现
8.3.标签管理
九、Operator
9.1.什么是PrometheusOperator
9.2.PrometheusOperator自定义监控项
9.3.配置PrometheusRule
十、AlterManager
10.1.基础入门
10.2.配置详解
十一、常见问题
Prometheus 联邦机制中的 out-of-order samples与 up 指标波动问题
十二、指导说明
PromQL查询函数参考
十三、可观测生态
用VictoriaMetrics替换Prometheus扛住百万级采集
十四、OpenTelemetry
传统 VM 下零代码OpenTelemetry可观测方案
本文档使用 MrDoc 发布
-
+
首页
用VictoriaMetrics替换Prometheus扛住百万级采集
在云原生体系全面普及的当下,监控系统已成为稳定性工程(SRE)与可观测性(Observability)的基础设施。随着企业规模不断扩大,业务组件、微服务实例、Kubernetes 集群节点以及各种基础设施设备的数量呈指数级增长,指标采集层的性能瓶颈逐渐成为可观测性领域的新挑战。 Prometheus 作为事实上的监控标准,生态成熟、部署简单、查询能力强。然而,它在架构设计上的一些“天然限制”也逐步暴露: * 单点架构限制水平扩展 * 高采集规模下出现内存膨胀、频繁 GC * Remote Write 在高压力下稳定性不足 * 无内置缓冲与去重机制,网络抖动时丢点严重 * 本地存储无法满足企业级数据保留要求 为彻底解决上述问题,我们在多套大规模 Kubernetes 集群与上千台物理机环境中,采用 **VictoriaMetrics + vmagent** 构建下一代企业级指标采集架构。经过多轮压测与灰度运行后,该方案成功支撑 **百万级以上样本(samples/s)** 的采集压力,实现了 Prometheus 的完全替代。 本文将详细介绍我们为何要替换 Prometheus、vmagent 集群的落地方案、生产级最佳实践以及最终带来的成本与稳定性收益。 # 一、 Prometheus体系瓶颈 随着业务规模增长,Prometheus 的问题从“偶发”变为“不堪重负”。以下是我们在生产环境中切实遇到的问题。 --- ### 1.1、单点问题 Prometheus 本身不支持集群模式,每实例负责自身抓取目标并本地存储: * 当 scrape targets 过多时,单实例 CPU 飙升 * 每秒 ingest 上限通常在 150k–300k samples/s(依配置差异) * 多个 Prometheus 之间数据孤立,查询需要联邦(Federation)或 Thanos 这使其在大规模场景下成本急剧增加。 --- ### 1.2、高负载问题 Prometheus 的 TSDB 高度依赖内存进行写入缓存与 block 构建,大量时间序列会导致: * 内存占用数十 GB 以上 * Go GC 暂停引发 scrape 超时 * CPU/内存资源成本持续升高 当 targets 超过 **10 万** 时,这个问题尤为严重。 ### 1.3、Remote Write不稳定问题 Prometheus 的 remote_write 是“尽力而为”的模式: * 无缓冲 * 无去重 * 无强一致性保证 * 后端波动、网络 jitter 时容易丢点 对于企业级监控来说,这不可接受。 --- ### 1.4、无企业级能力问题 Prometheus 缺乏以下能力: * 远程后端写入失败时的本地缓冲 * 网络恢复后自动补发 * 指标去重(如多机部署的高可用写入) * 多后端写入 * 写入限流 * 多租户隔离 这些能力对于大规模场景几乎是“基础要求”。 --- # 二、 vmagent高性能指标采集引擎 VictoriaMetrics 生态完全兼容 Prometheus 的 scrape_ configs、服务发现、remote_write 协议,同时提供 Prometheus 所缺乏的企业级能力。 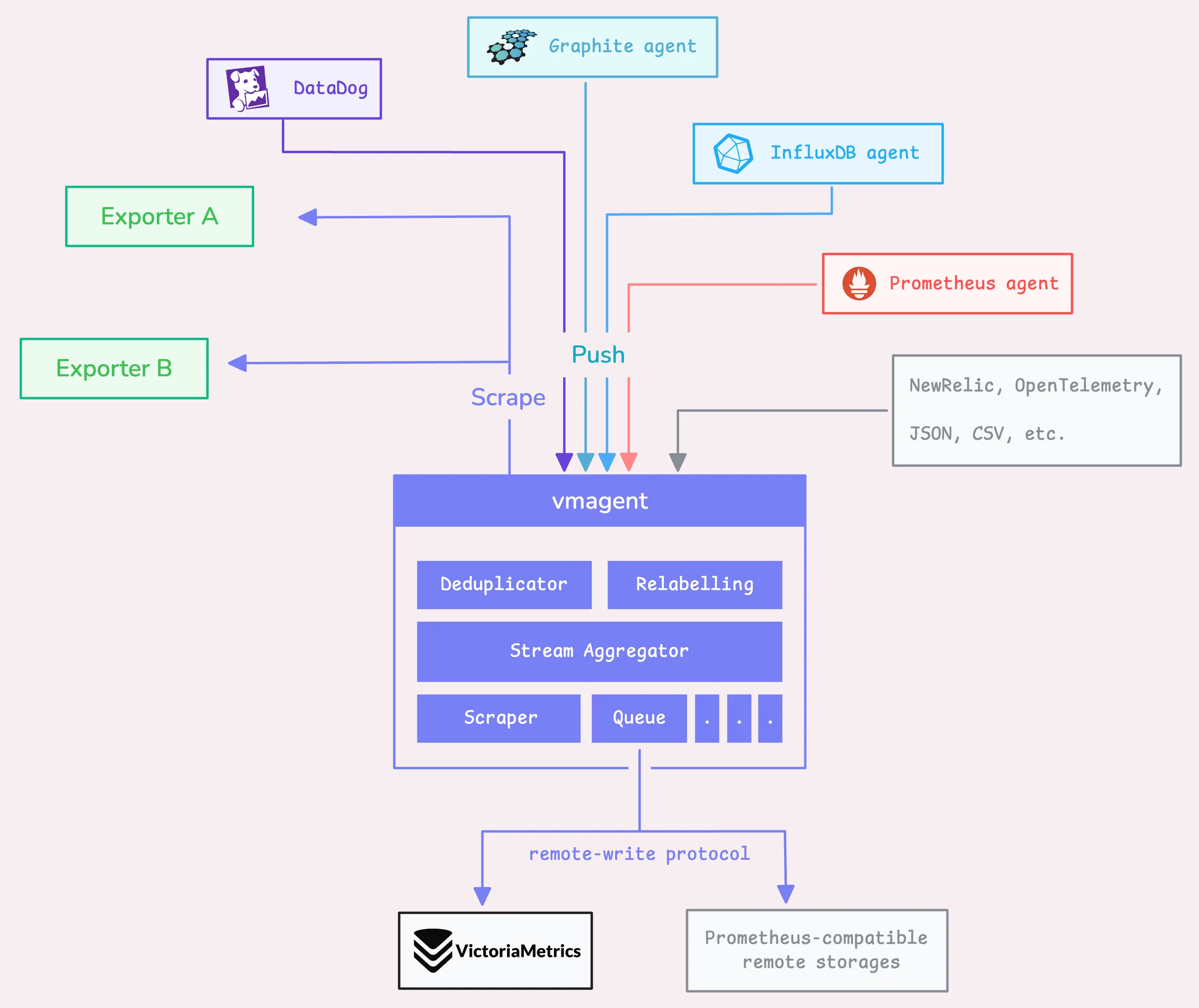 ### 2.1、 vmagent 的核心优势 1. 极高吞吐能力(可达数百万 samples/s 官方与社区实测均能轻松超过 Prometheus 数倍以上的吞吐能力。 2. 低内存占用 VM 优化的 TSDB 写入算法 + 内存效率优化,使其在相同采集规模下内存减少 **50%~80%**。 3. 强健稳定的 Remote Write 包括: - 本地磁盘缓冲(落盘重试) - 后端故障时不丢数据 - 自动补发 - 多后端写入(例如同时写 VM + Prometheus + Kafka) 4. 内置指标去重 在多副本采集架构中,可自动去除重复样本。 5. 极简部署、开箱即用 --- # 三、 vmagent构建企业级集群方案 最终落地的架构如下: | 组件名称 | 主要用途 / 作用 | 默认端口(你提供) | 部署位置 | 是否必须组件 | 说明 | | ------------- | ----------------------------------------------------------------------------------- | --------- | ---------------- | ------------------------------------- | ------------------------------------------------------ | | **vmagent** | 指标采集器 + RemoteWrite 汇聚器。支持 Prometheus 配置、服务发现、remote_write 接收/转发。可作为 Prometheus 代理。 | **9144** | **客户端(采集端)或中转层** | 否(可用 Prometheus 替代) | 能收、能转发、能缓冲,支持 Prometheus 的所有采集特性,比 Prometheus 更轻量和高性能。 | | **vmalert** | 报警规则(Recording rules / Alerting rules)执行器,兼容 Prometheus rule 语法。也可用来生成时序规则的指标。 | **9145** | **服务端** | 否(也可用 Prometheus Alertmanager + rule) | 查询 vmselect,从 VMTS 获取数据,最终发告警给 Alertmanager。 | | **vmauth** | 统一鉴权网关,负责 OAuth/basic auth/API key / 访问控制,流量转发至 vmselect/vminsert/vmagent 等。 | **9146** | **服务端网关层** | 否 | 用于多租户、多用户访问控制,比如不同团队隔离数据查询或写入。 | | **vminsert** | **数据写入节点**,负责接收 remote_write 数据并写入 vmstorage。 | **9147** | **服务端(写入层)** | ✔ **集群必需** | 和 vmselect 分层架构。所有写入操作都通过 vminsert。 | | **vmrestore** | 备份恢复工具,从对象存储或本地读取快照恢复到 VMTS。 | **9148** | **服务端工具组件** | 否 | 用于 disaster recovery(DR)或迁移。非在线服务。 | | **vmselect** | **查询节点**,负责执行所有查询(PromQL / MetricsQL)。读取数据来自 vmstorage。 | **9149** | **服务端(查询层)** | ✔ **集群必需** | 对所有 Prometheus / Grafana 查询提供响应。 | | **vmstorage** | **核心存储节点**,负责接收写入、存储样本、压缩、查询索引。VictoriaMetrics 的真正 TSDB 引擎。 | **9150** | **服务端(存储层)** | ✔ **集群必需** | VM 的底层存储引擎,决定性能和容量。可水平扩容。 | 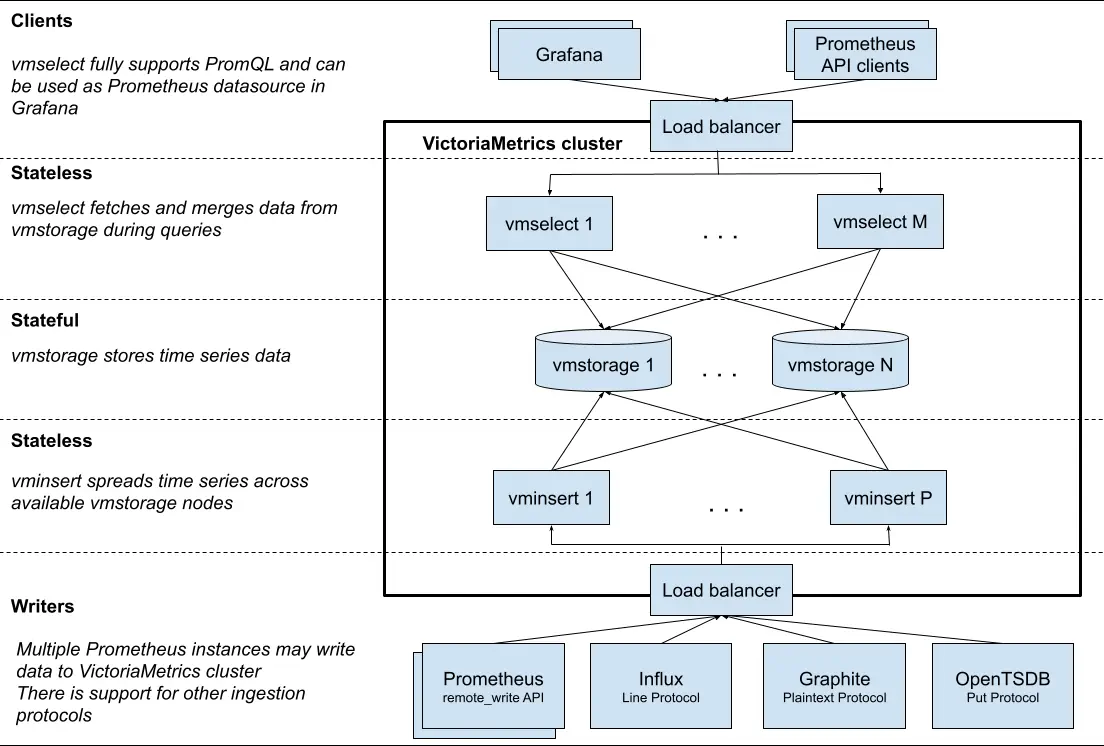 --- ### vmstorage 部署 下载地址 ``` https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.131.0/victoria-metrics-linux-amd64-v1.131.0-cluster.tar.gz ``` ```bash cat <<EOF | sudo tee /prometheus/service/vmstorage.service [Unit] Description=VictoriaMetrics Storage After=network.target [Service] User=root Group=root ExecStart=/prometheus/sbin/vmstorage \\ -envflag.enable=true \\ -storage.minFreeDiskSpaceBytes=20GB \\ -loggerTimezone=Asia/Shanghai \\ -memory.allowedPercent=80 \\ -storageDataPath=/prometheus/data/vmstorage/disk1 \\ -retentionPeriod=30d \\ -httpListenAddr=:9150 \\ -vminsertAddr=:19147 \\ -vmselectAddr=:19149 \\ -dedup.minScrapeInterval=15s \\ -loggerFormat=json Restart=always [Install] WantedBy=multi-user.target EOF ``` >说明 > - httpListenAddr=:9150 # 开放HTTP端口用于监控和管理(默认无认证) > - vminsertAddr=:19147 # 接收 vminsert 组件写入的TCP端口 > - vmselectAddr=:19149 # 响应 vmselect 组件查询的TCP端口 ``` chmod +x /prometheus/service/vmstorage.service && ln -fs /prometheus/service/vmstorage.service /usr/lib/systemd/system/ systemctl enable --now vmstorage.service && systemctl status vmstorage.service ``` ### 3.1、vminsert 部署规范 ```bash cat <<END >/prometheus/service/vminsert.service [Unit] Description=VictoriaMetrics vminsert service After=network.target [Service] Type=simple User=root Group=root Restart=always ExecStart=/prometheus/sbin/vminsert \\ -httpListenAddr=:9147 \\ -storageNode=:19147 \\ -loggerFormat=json \\ -loggerTimezone=Asia/Shanghai \\ -maxConcurrentInserts=256 \\ -insert.maxQueueDuration=60s \\ -maxLabelsPerTimeseries=50 \\ PrivateTmp=yes NoNewPrivileges=yes ProtectSystem=full [Install] WantedBy=multi-user.target END ``` ``` chmod +x /prometheus/service/vminsert.service && ln -fs /prometheus/service/vminsert.service /usr/lib/systemd/system/ systemctl enable --now vminsert.service && systemctl status vminsert.service ``` ### 3.1、vmselect 部署规范 ``` cat <<END >/etc/systemd/system/vmselect.service [Unit] Description=VictoriaMetrics vmselect service After=network.target [Service] Type=simple User=root Group=root Restart=always ExecStart=/prometheus/sbin/vmselect \\ -storageNode=:19149 \\ -cacheDataPath=/prometheus/data/vmselect \\ -httpListenAddr=:9149 \\ -search.maxQueryDuration=30s PrivateTmp=yes NoNewPrivileges=yes ProtectSystem=full [Install] WantedBy=multi-user.target END ``` ``` chmod +x /prometheus/service/vmselect.service && ln -fs /prometheus/service/vmselect.service /usr/lib/systemd/system/ systemctl enable --now vmselect.service && systemctl status vmselect.service ``` ### 3.1、vmagent 部署规范 **目录结构** ```bash sudo mkdir -p /prometheus/{bin,etc,tmp,logs} ``` --- **下载与安装(企业内可使用制品库)** ```bash wget https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.131.0/vmutils-linux-amd64-v1.131.0.tar.gz tar xf vmutils-linux-amd64-v1.128.0.tar.gz -C /tmp/ cp /tmp/vmagent-prod /prometheus/bin/vmagent ``` --- **Scrape 配置(核心示例)** ```yaml global: scrape_interval: 15s scrape_timeout: 10s external_labels: cluster: prod dc: sh-bgp-a scrape_configs: - job_name: vmagent-self metrics_path: /metrics static_configs: - targets: ["172.139.20.181:8429"] - job_name: kubernetes-nodes kubernetes_sd_configs: - role: node relabel_configs: - action: labeldrop regex: "controller.*" ``` --- **systemd 配置** ```ini [Unit] Description=VictoriaMetrics vmagent service After=network.target [Service] Type=simple User=root Restart=always ExecStart=/prometheus/bin/vmagent \ -httpListenAddr=:8429 \ -promscrape.config=/prometheus/bin/vmagent.yml \ -remoteWrite.tmpDataPath=/prometheus/tmp \ -remoteWrite.url=http://172.139.20.200:18480/insert/0/prometheus \ -remoteWrite.url=http://172.139.20.201:18480/insert/0/prometheus \ -remoteWrite.queues=8 \ -remoteWrite.maxDiskUsagePerURL=50GB PrivateTmp=yes ProtectHome=yes NoNewPrivileges=yes ProtectSystem=full [Install] WantedBy=multi-user.target ``` --- **启动服务** ```bash sudo systemctl daemon-reload sudo systemctl enable vmagent --now ``` --- # 四、高可用实现 大规模企业级落地的关键,在于架构必须保证 **任一节点故障不丢指标、不重复写入、不中断服务**。 ### 4.1、多副本 vmagent 采集 策略: * 同一个 scrape target 被 2 个以上 vmagent 抓取 * remote_write 端自动去重(由 VictoriaMetrics 实现) 优点: * 单 vmagent 故障不影响采集 * VM 默认利用 `__replica__` 标签去重,保证写入幂等 --- ### 4.2、本地缓冲与批量补发机制** vmagent 支持: * remote write 失败时缓存在磁盘 * 后端恢复后自动补发 * 可设置上限,例如 50GB per URL 生产环境验证: > 后端 VM cluster 升级停机 15 分钟 > → vmagent 全面缓存 > → 后端恢复后 3 分钟内全部补齐 > → 无一条指标丢失 Prometheus 在同样场景下几乎必然丢点。 ### 4.3、支持多后端 remote_write 企业级典型模式: * 写主 VictoriaMetrics(生产查询链路) * 写备份 VictoriaMetrics(DR 灾备) * 写 Kafka(大数据加工、AIOps) * 写 S3(离线归档) vmagent 可天然支持多后端写入。 --- ### 4.4、统一服务发现 支持: * Kubernetes(Pod/Node/Endpoint) * Consul * EC2 * Azure / GCE * DNS * Static config 可以做到**跨机房、跨集群统一采集**。 --- ### 4.2、强化隔离与资源控制 vmagent 提供: * 抓取限流 * remote_write 限流 * 内存配额 * 并发队列限制 在多租户场景中极为重要。 # 五、成本、稳定性与架构收益 经过多轮压测和生产运行,vmagent + VictoriaMetrics 带来的收益非常显著。 ### 5.1、性能与稳定性 | 项目 | Prometheus | vmagent | | ---------------- | ------------------- | ----------------- | | 最大采集能力 | 150k–300k samples/s | **>1M samples/s** | | 内存占用 | 20–40GB | **4–8GB** | | remote_write 稳定性 | 易丢点 | **强一致补发机制** | | 去重 | 不支持 | **内置去重** | | 多后端写入 | 不支持 | 支持 | --- ### 5.2、 成本收益 至少降低 **60% 以上** 的机器成本。 减少 Prometheus 实例数量 → 减少存储成本 → 减少报警链路复杂性。
Nathan
2025年12月8日 18:05
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码