Prometheus
一、基础简介
1.1.prometheus简介
1.2.数据模型
1.3.指标类型
1.4.Jobs和Instances
二、安装部署
2.1.rpm部署监控组件
2.2.docker部署监控组件
三、PromSQL
3.1.PromQL基本使用
3.2.Prometheus基础查询
3.3.查询操作符
3.4.内置函数
3.5.在HTTPAPI中使用PromQL
3.6.最佳实践
四、告警处理
4.1.告警简介
4.2.自定义Prometheus告警规则
4.3.常见告警规则
4.4.部署Alertmanager
4.5.Alertmanager配置概述
4.6.基于标签的告警处理路由
4.7.使用Receiver接收告警信息
4.8.自定义告警模板
4.9.屏蔽告警通知
4.10.使用RecodingRules优化性能
五、Exporter
5.1.exporter
5.2.NodeExporter
5.3.ProcessExporter
5.4.cAdvisor
5.5.MysqlExporter
5.6.BlackboxExporter
5.7.ProcessExporter
5.8.Ipmiexport
5.9.Pushgateway
PostgresExporter
六、Grafana
6.1.grafana基本概念
6.2.创建dashboard与Panel
6.3.变化趋势:Graph面板
6.4.graph面板常用操作
6.5.分布统计:Heatmap面板
6.6.当前状态:SingleStat面板
6.7.变量
6.8.grafana报警
七、集群高可用
7.1.本地存储
7.2.远程存储
7.3.联邦集群
7.4.prometheus高可用
7.5.Alertmanager高可用
VictoriaMetrics 集群在边缘场景下的部署实践
八、服务发现
8.1.Prometheus与服务发现
8.2.基于文件的服务发现
8.3.标签管理
九、Operator
9.1.什么是PrometheusOperator
9.2.PrometheusOperator自定义监控项
9.3.配置PrometheusRule
十、AlterManager
10.1.基础入门
10.2.配置详解
十一、常见问题
Prometheus 联邦机制中的 out-of-order samples与 up 指标波动问题
十二、指导说明
PromQL查询函数参考
十三、可观测生态
用VictoriaMetrics替换Prometheus扛住百万级采集
十四、OpenTelemetry
传统 VM 下零代码OpenTelemetry可观测方案
本文档使用 MrDoc 发布
-
+
首页
10.1.基础入门
## 一、prometheus告警介绍 ### 1. 组件介绍 prometheus整个监控系统中,prometheus只负责将数据采集和生成告警信息,而告警信息的处理是由Alertmanager负责处理。<br />在Prometheus中定义好告警规则后,Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。<br />Alertmanager负责接收并处理来自Prometheus Server的告警信息。对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件、Slack、webhook等多种通知方式的支持,同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。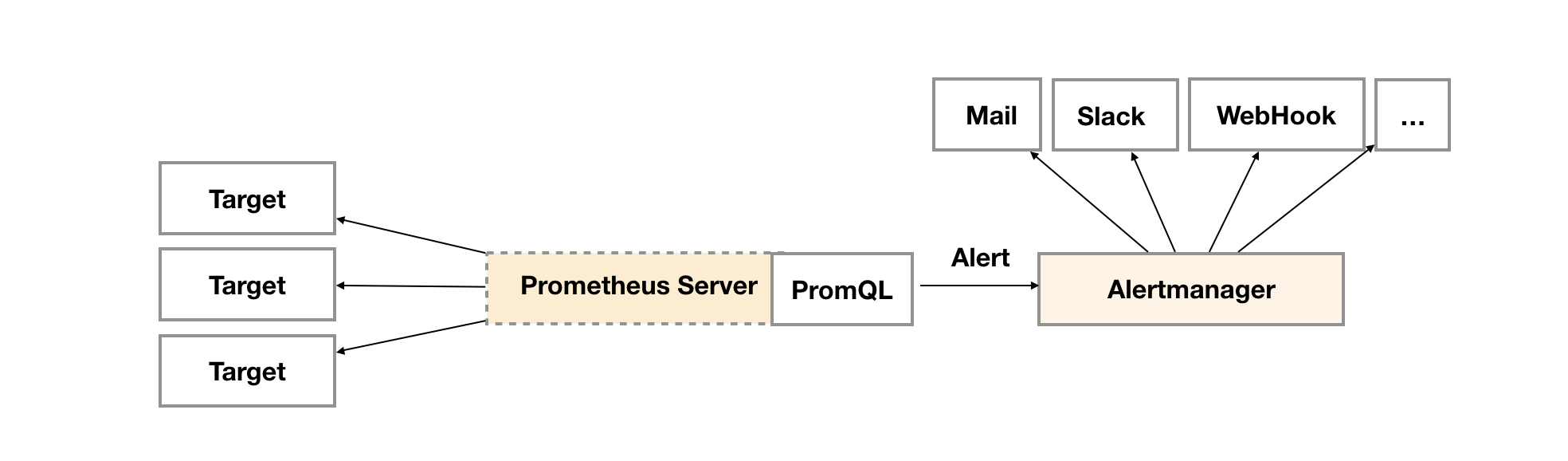 ### 2. Alertmanager功能介绍 Alertmanager除了提供基本的告警通知能力以外,还提供了告警分组、告警抑制以及告警静默等功能: - 告警分组 分组机制可以将同个分组下的多个告警合并到一个告警中进行发送,减少通知骚扰。例如在发生了网络故障,导致大量的服务间无法通信,此时就会有大量告警发送到Alertmanager,运维人员一次性接受大量的告警通知,反而无法对问题进行快速定位,这并不是用户希望看到的,此时可以按服务维度进行分组,将这些告警组合成一个通知。 - 告警抑制 当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制,避免发生某个故障出现后导致其他一系列故障一起告警形成告警风暴的问题。例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。 - 告警静默 让同时间段内的相同告警不再重复发出,根据标签对告警进行静默处理。例如对服务进行停机维护期间可设置告警静默,避免重复多次发送告警。 ## 二、Alertmanager部署 ### 1. 创建configmap资源 - 此处先用官方默认的配置,至于每个配置的含义,会在后面的文章中具体讲解,也会根据需求更改相关配置。 ``` apiVersion: v1 kind: ConfigMap metadata: name: alertmanager-conf namespace: monitoring data: config.yaml: |- route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] ``` ### 2. 创建Alertmanager - alertmanager-deployment(将上面创建的alertmanager-conf这个configmap资源对象volume的形式挂载到/etc/alertmanager目录,并挂载空目录/alertmanager用于存放数据) ``` apiVersion: apps/v1 kind: Deployment metadata: name: alertmanager namespace: monitoring spec: replicas: 1 selector: matchLabels: app: alertmanager template: metadata: name: alertmanager labels: app: alertmanager spec: containers: - name: alertmanager image: prom/alertmanager:v0.23.0 imagePullPolicy: IfNotPresent resources: limits: memory: "512Mi" cpu: "1000m" requests: memory: "128Mi" cpu: "500m" args: - '--config.file=/etc/alertmanager/config.yaml' - '--storage.path=/alertmanager' ports: - name: alertmanager containerPort: 9093 volumeMounts: - name: alertmanager-conf mountPath: /etc/alertmanager - name: alertmanager mountPath: /alertmanager affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - alertmanager topologyKey: "kubernetes.io/hostname" volumes: - name: alertmanager-conf configMap: name: alertmanager-conf - name: alertmanager emptyDir: {} ``` - alertmanager-svc ``` apiVersion: v1 kind: Service metadata: name: alertmanager namespace: monitoring labels: app: alertmanager spec: selector: app: alertmanager ports: - name: alertmanager protocol: TCP port: 9093 targetPort: 9093 ``` - alertmanager-ingress(此处以traefik为例) ``` apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: alertmanager namespace: monitoring spec: routes: - match: Host(`alertmanager.local.com`) kind: Rule services: - name: alertmanager port: 9093 ``` ### 3. 关联Prometheus与Alertmanager - Alertmanager部署完成后,接下来修改prometheus配置,添加Alertmanager地址,让prometheus能访问Alertmanager ``` apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: monitoring data: prometheus.yaml: |- global: scrape_interval: 15s evaluation_interval: 15s rule_files: - /etc/prometheus/rules/*.yaml alerting: alertmanagers: - static_configs: - targets: ["alertmanager:9093"] scrape_configs: ………… ``` ### 4. 测试验证 - 访问Alertmanager地址 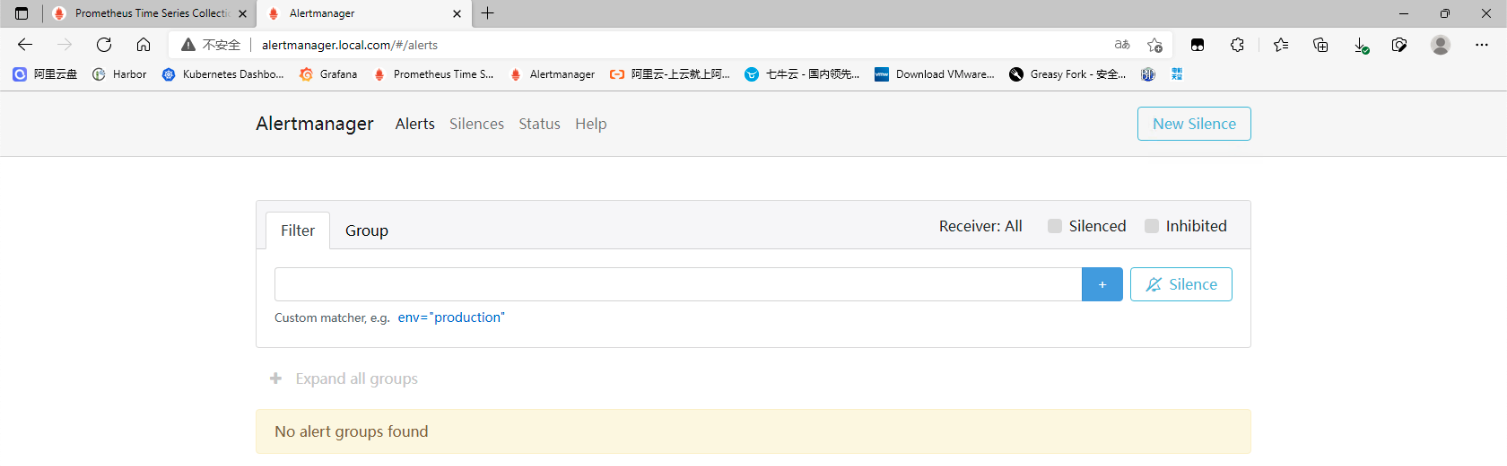<br />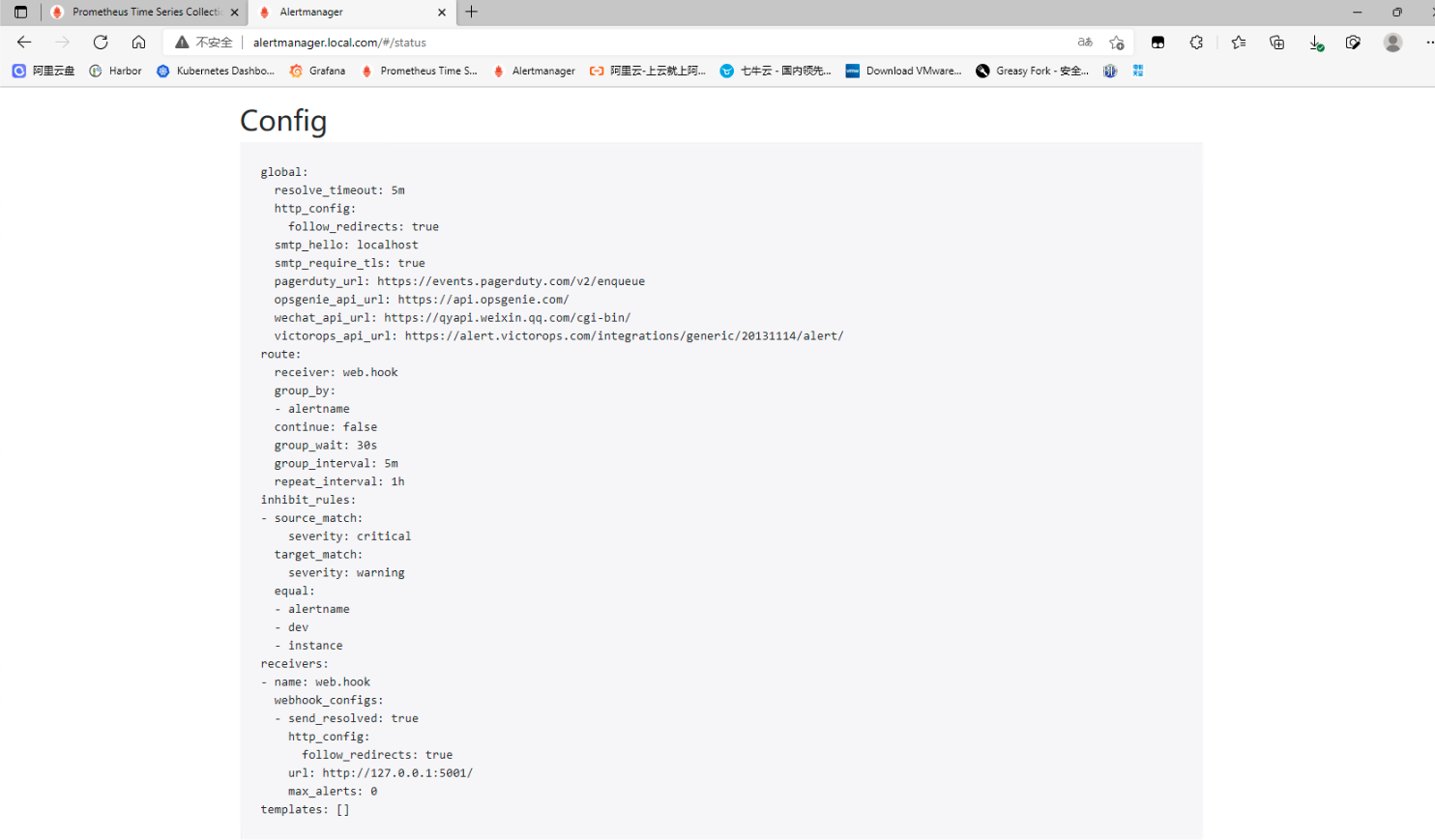 - 访问prometheus的/status,查看Alertmanager信息 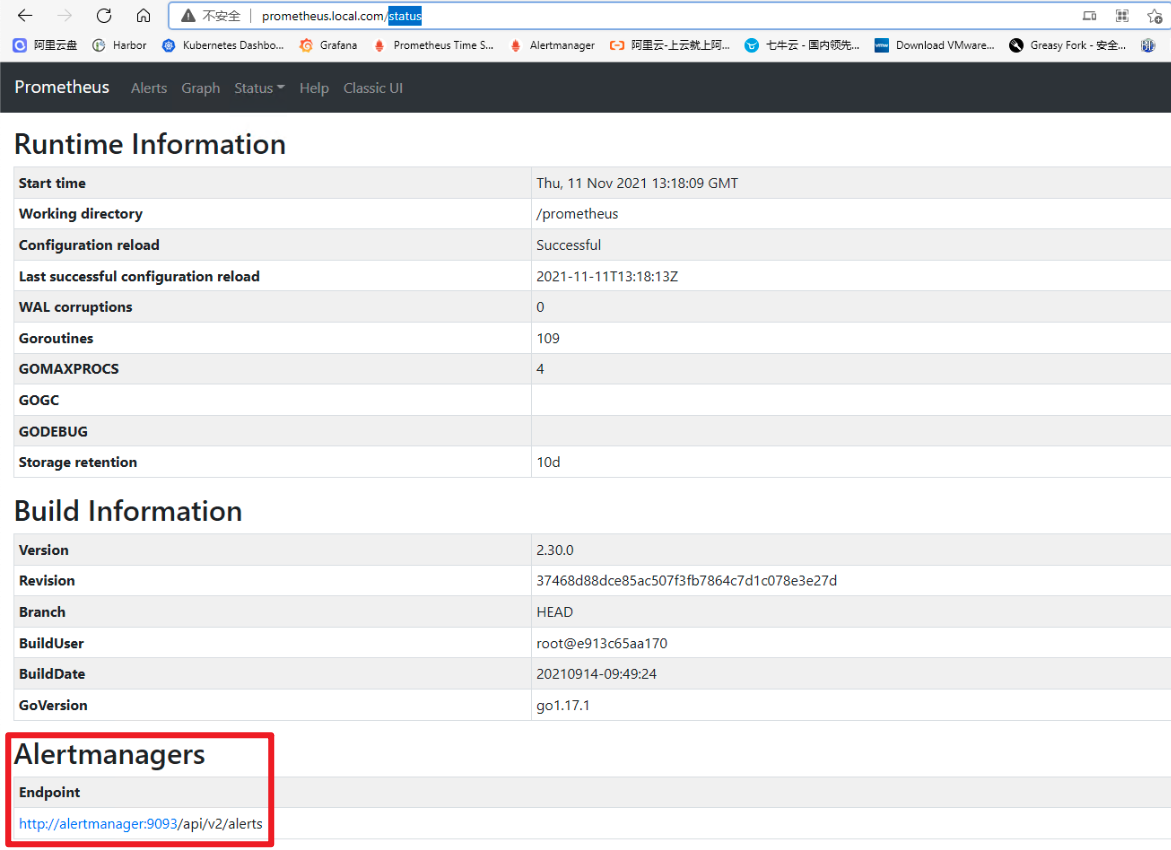 - 至此,Alertmanager部署基本完成 ## 三、配置prometheus告警规则 ### 1. 告警配置格式 Prometheus中的告警规则是基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。 ``` groups: - name: 告警分组名 rules: - alert: 告警规则的名称 expr: PromQL表达式,告警触发条件,用于计算是否有时间序列满足该条件。 for: 评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。避免因为网络拥塞等原因导致偶尔异常后立即触发告警 labels: # 自定义标签,允许用户指定要附加到告警上的一组附加标签。 severity: 自定义标签-告警等级 annotations: # 告警附加信息,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。 summary: 描述告警的概要信息 description: 用于描述告警的详细信息 ``` ### 2. 告警模板 为了让告警信息具有更好的可读性,prometheus支持使用变量替换annotations中的告警附加信息<br />通过$labels.<labelname>变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。 ``` groups: - name: node-alert rules: - alert: node status is WODN expr: up{job="node_exporter"} == 0 for: 5m labels: severity: emergency instance: "{{ $labels.instance }}" annotations: summary: "node: {{ $labels.instance }} down" description: "{{$labels.instance}} down more than 5 minutes" value: "{{ $value }}" ``` - 这个告警的意思是查询node_exporter的up状态,如果为0,说明节点宕机,发出告警。(当前节点都是up状态, up{job=“node_exporter”} == 1可以查询到4台主机up信息) 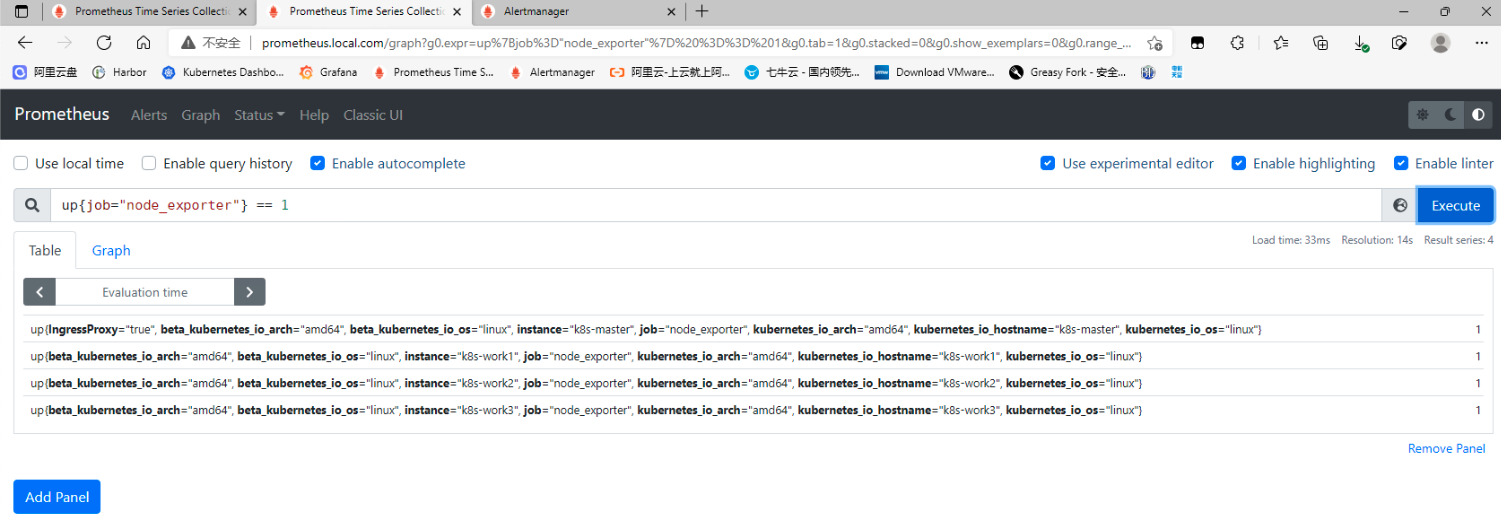 ### 3. prometheus告警配置 - 创建一个configmap资源,用于存放prometheus告警配置 ``` apiVersion: v1 kind: ConfigMap metadata: name: prometheus-rule labels: name: prometheus-rule namespace: monitoring data: alert-rules.yaml: |- groups: - name: node-alert rules: - alert: node status is WODN expr: up{job="node_exporter"} == 0 for: 5m labels: severity: emergency instance: "{{ $labels.instance }}" annotations: summary: "node: {{ $labels.instance }} down" description: "{{$labels.instance}} down more than 5 minutes" value: "{{ $value }}" ``` - 修改prometheus配置文件,指定rule文件路径 ``` apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: monitoring data: prometheus.yaml: |- global: scrape_interval: 15s evaluation_interval: 15s rule_files: - /etc/prometheus/rules/*.yaml alerting: alertmanagers: - static_configs: - targets: ["alertmanager:9093"] scrape_configs: ………… ``` - 修改prometheus资源清单,将rule文件挂载 ``` apiVersion: apps/v1 kind: StatefulSet metadata: name: prometheus namespace: monitoring labels: app: prometheus spec: serviceName: prometheus-headless podManagementPolicy: Parallel replicas: 1 selector: matchLabels: app: prometheus template: metadata: labels: app: prometheus spec: serviceAccountName: prometheus containers: - name: prometheus image: prom/prometheus:v2.30.0 imagePullPolicy: IfNotPresent args: - --config.file=/etc/prometheus/config/prometheus.yaml - --storage.tsdb.path=/prometheus - --storage.tsdb.retention.time=10d - --web.route-prefix=/ - --web.enable-lifecycle - --storage.tsdb.no-lockfile - --storage.tsdb.min-block-duration=2h - --storage.tsdb.max-block-duration=2h - --log.level=debug ports: - containerPort: 9090 name: web protocol: TCP livenessProbe: httpGet: path: /-/healthy port: web scheme: HTTP readinessProbe: httpGet: path: /-/ready port: web scheme: HTTP volumeMounts: - mountPath: /etc/prometheus/config name: prometheus-config - mountPath: /prometheus name: data - name: prometheus-rule mountPath: /etc/prometheus/rules volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-rule configMap: name: prometheus-rule volumeClaimTemplates: - metadata: name: data spec: accessModes: - ReadWriteOnce storageClassName: local-storage resources: requests: storage: 10Gi ``` ### 4. 验证测试 - 通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规则,以及其当前所处的活动状态。处于INACTIVE 状态,表示一切正常不会触发告警。处于 PENDING 状态,表示已经满足告警条件,但在评估等待期间,如果持续异常,报警即将被激活。处于 FIRING 状态,表示报警已经被激活了。 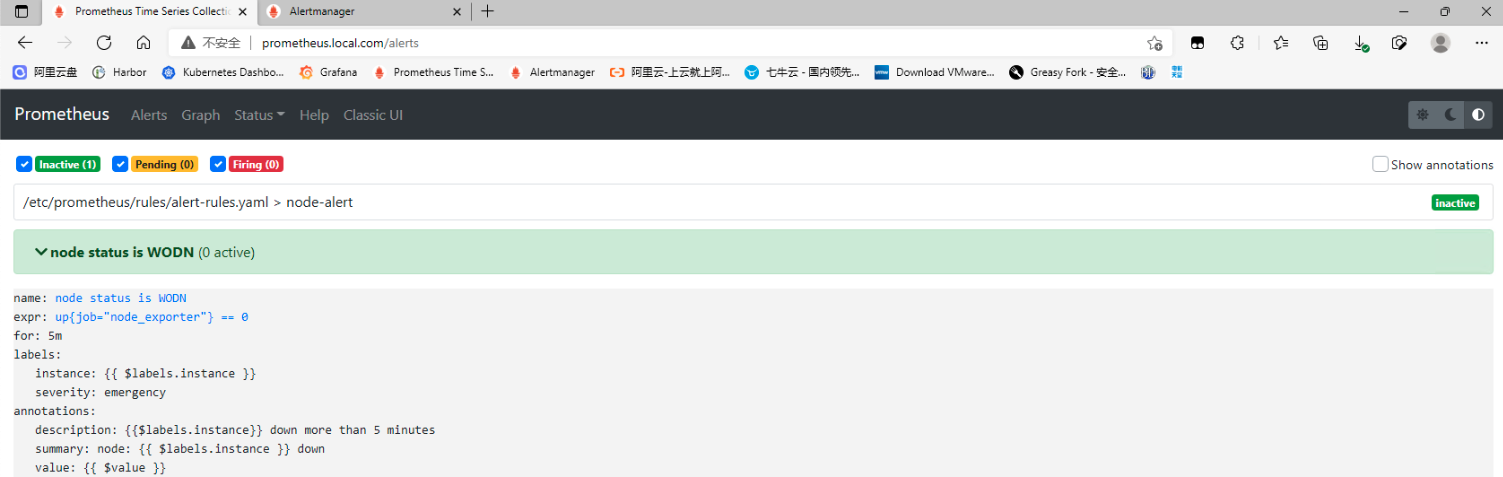 - 接下来关闭集群中一个节点,模拟宕机故障 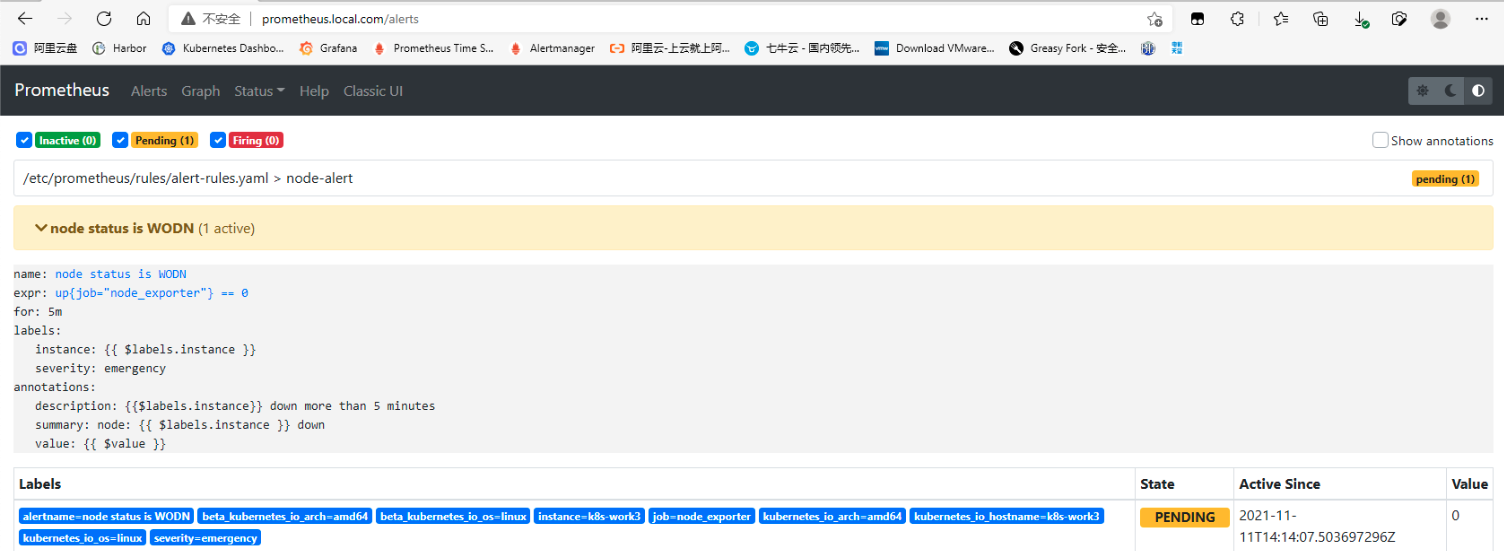 - 此时已处于 PENDING 状态,因为上面设置了for:5m,需要down的状态持续5分钟,才会发出告警通知 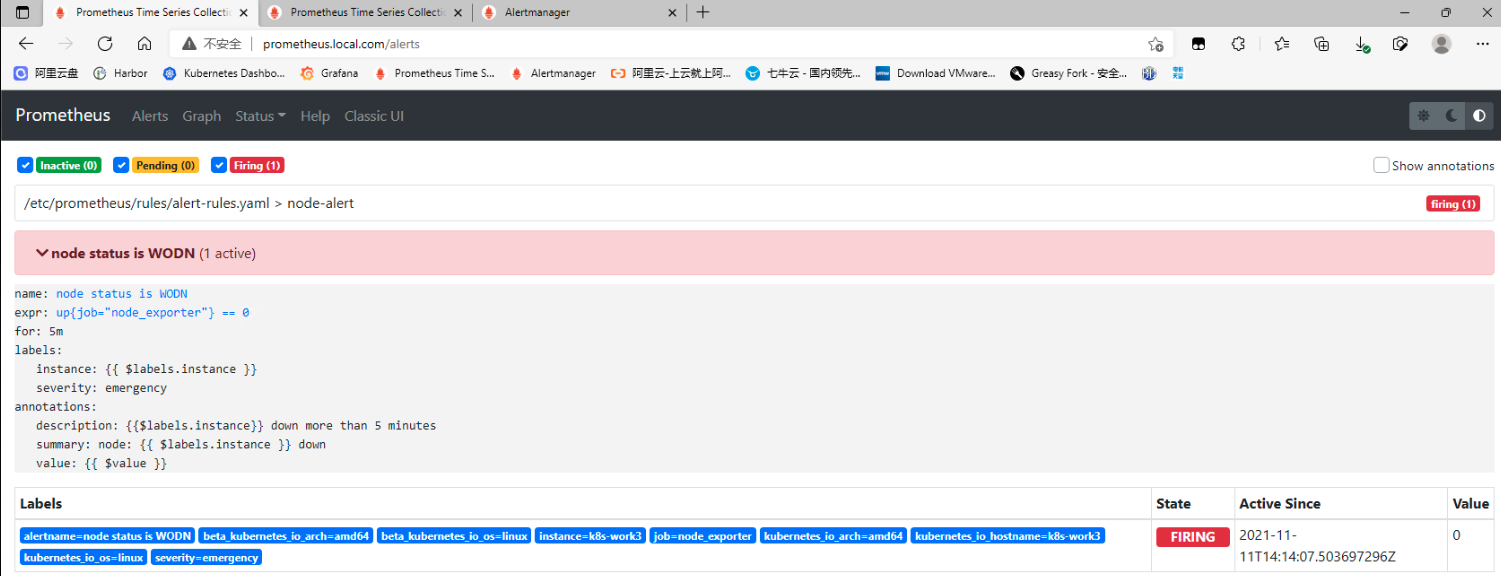 - 此时在Alertmanager中就可以看到详细的告警信息 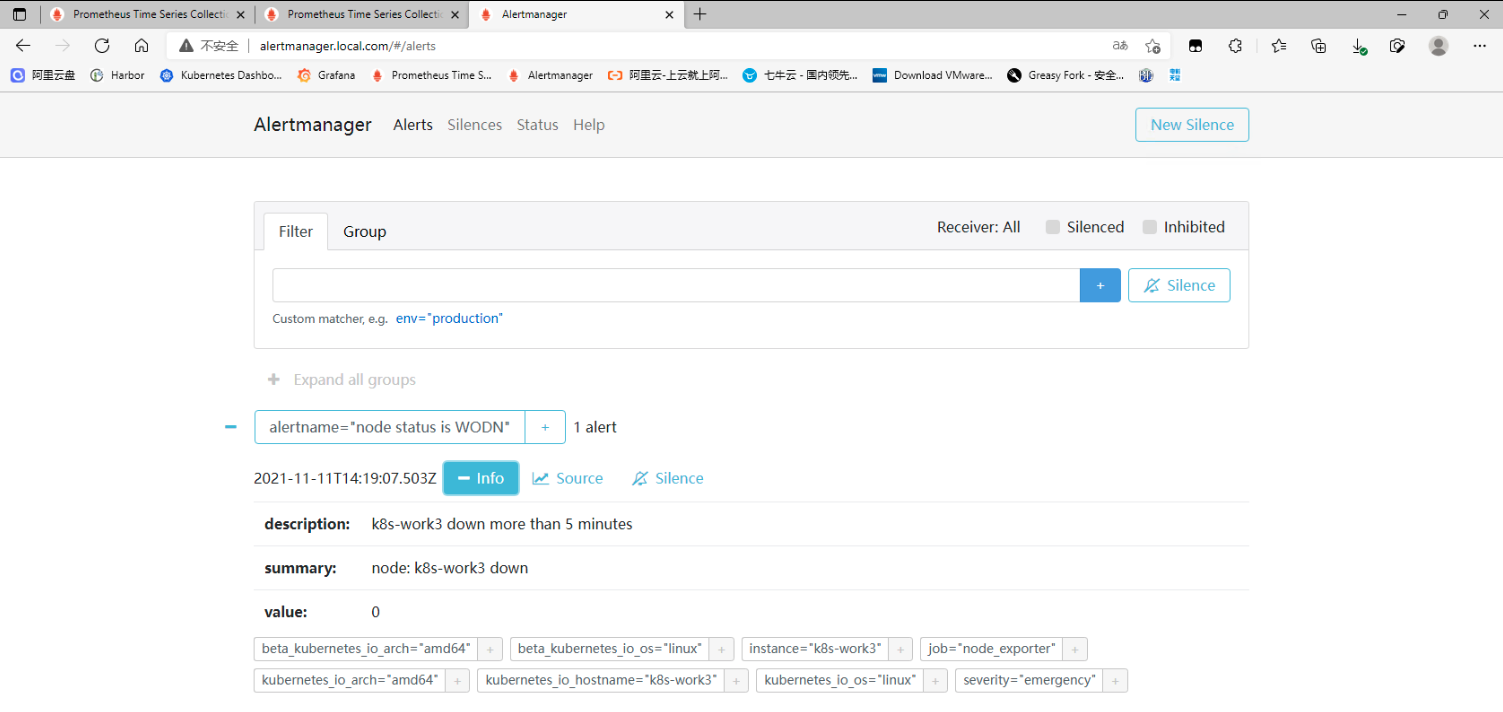 - 除了在Alertmanager中查看告警信息,Prometheus也会将它们存储到时间序列ALERTS{}中。 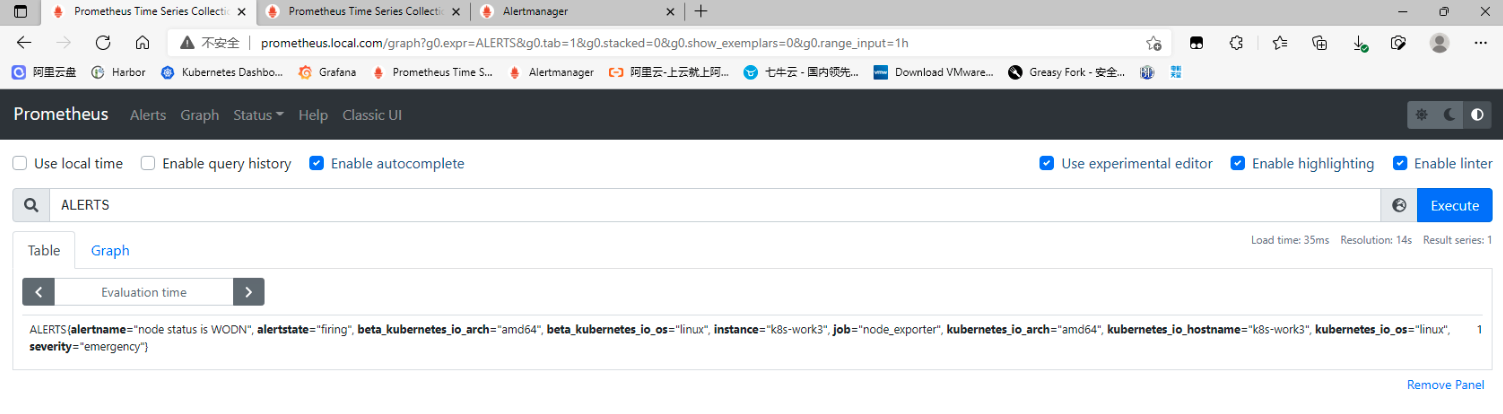
Nathan
2024年8月24日 15:09
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码