Prometheus
一、基础简介
1.1.prometheus简介
1.2.数据模型
1.3.指标类型
1.4.Jobs和Instances
二、安装部署
2.1.rpm部署监控组件
2.2.docker部署监控组件
三、PromSQL
3.1.PromQL基本使用
3.2.Prometheus基础查询
3.3.查询操作符
3.4.内置函数
3.5.在HTTPAPI中使用PromQL
3.6.最佳实践
四、告警处理
4.1.告警简介
4.2.自定义Prometheus告警规则
4.3.常见告警规则
4.4.部署Alertmanager
4.5.Alertmanager配置概述
4.6.基于标签的告警处理路由
4.7.使用Receiver接收告警信息
4.8.自定义告警模板
4.9.屏蔽告警通知
4.10.使用RecodingRules优化性能
五、Exporter
5.1.exporter
5.2.NodeExporter
5.3.ProcessExporter
5.4.cAdvisor
5.5.MysqlExporter
5.6.BlackboxExporter
5.7.ProcessExporter
5.8.Ipmiexport
5.9.Pushgateway
PostgresExporter
六、Grafana
6.1.grafana基本概念
6.2.创建dashboard与Panel
6.3.变化趋势:Graph面板
6.4.graph面板常用操作
6.5.分布统计:Heatmap面板
6.6.当前状态:SingleStat面板
6.7.变量
6.8.grafana报警
七、集群高可用
7.1.本地存储
7.2.远程存储
7.3.联邦集群
7.4.prometheus高可用
7.5.Alertmanager高可用
VictoriaMetrics 集群在边缘场景下的部署实践
八、服务发现
8.1.Prometheus与服务发现
8.2.基于文件的服务发现
8.3.标签管理
九、Operator
9.1.什么是PrometheusOperator
9.2.PrometheusOperator自定义监控项
9.3.配置PrometheusRule
十、AlterManager
10.1.基础入门
10.2.配置详解
十一、常见问题
Prometheus 联邦机制中的 out-of-order samples与 up 指标波动问题
十二、指导说明
PromQL查询函数参考
十三、可观测生态
用VictoriaMetrics替换Prometheus扛住百万级采集
十四、OpenTelemetry
传统 VM 下零代码OpenTelemetry可观测方案
本文档使用 MrDoc 发布
-
+
首页
5.9.Pushgateway
# 一、Pushgateway 简介 1. Pushgateway 是 Prometheus 生态中一个重要工具,使用它的原因主要是: - Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。 - 在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。 2. pushgateway一些弊端: - 将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。 - Prometheus 拉取状态 up 只针对 pushgateway, 无法做到对每个节点有效。 - Pushgateway 可以持久化推送给它的所有监控数据。 - 即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。 3. 拓扑图 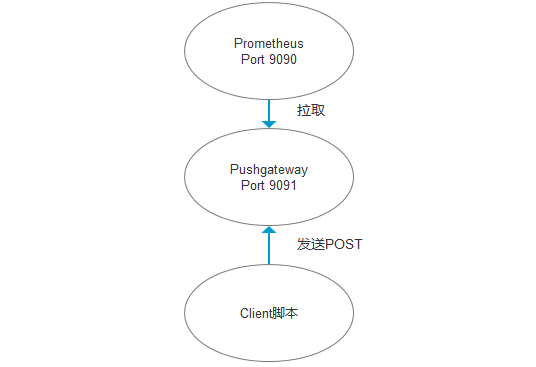 # 二、部署pushgetway - [下载链接](https://prometheus.io/download/#pushgateway) 1. 解压到/usr/local下 # tar -zxvf pushgateway-1.2.0.linux-amd64.tar.gz 1. 启动Blackbox Exporter # ./pushgateway 1. 访问服务器9091端口  # 三、与Prometheus集成 1. 修改/etc/prometheus/prometheus.yml,将cAdvisor添加监控数据采集任务目标当中:  2. 重新启动Prometheus服务: 3. 在Prometheus UI中查看到当前所有的Target状态:  # 四、数据管理 1. 向 {job="some_job"} 添加单条数据: - 客户端执行如下命令,将数据推送到pushgetway # echo "some_metric 3.14" | curl --data-binary @- [http://127.0.0.1:9091/metrics/job/some_job](http://127.0.0.1:9091/metrics/job/some_job) - --data-binary 表示发送二进制数据,它是使用POST方式发送的! - pushgetway查看数据  1. 删除某个组下的某实例的所有数据: curl -X DELETE [http://127.0.0.1:9091/metrics/job/some_job/instance/some_instance](http://127.0.0.1:9091/metrics/job/some_job/instance/some_instance) 1. 删除某个组下的所有数据: curl -X DELETE [http://127.0.0.1:9091/metrics/job/some_job](http://127.0.0.1:9091/metrics/job/some_job) 1. 注意事项: - pushgateway 中的数据我们通常按照 job 和 instance 分组分类,所以这两个参数不可缺少。 - 在 prometheus 中配置 pushgateway 的时候,需要添加 honor_labels: true 参数, 从而避免收集数据本身的 job 和 instance 被覆盖。 - 注意,为了防止 pushgateway 重启或意外挂掉,导致数据丢失,我们可以通过 -persistence.file 和 -persistence.interval 参数将数据持久化下来。 # 五、shell脚本实例 1. 实现线程总数监控 - 编写客户端shell脚本 ```bash #!/bin/bash instance_name=`hostname -f | cut -d'.' -f1` #提取主机名保存到instance标签 if [ $instance_name == "localhost" ];then #要求机器名不能是localhost,不然标签无法区分 echo "Must FQDN hostname" exit 1 fi label="count_thread_sum" # 定一个新的 key count_thread_sum=`ps -efL | wc -l` #获取新key数值为netstat中wait 的数量 echo "$label : $count_thread_sum" echo "$label $count_thread_sum" | curl --data-binary @- http://127.0.0.1:9091/metrics/job/pushgateway/instance/$instance_name ``` - 设置linux计划任务,每30秒执行一次 * * * * * sleep 30; /root/pushgateway-thread-sum.sh >> /var/log/pushgateway.log - pushgetway查看数据 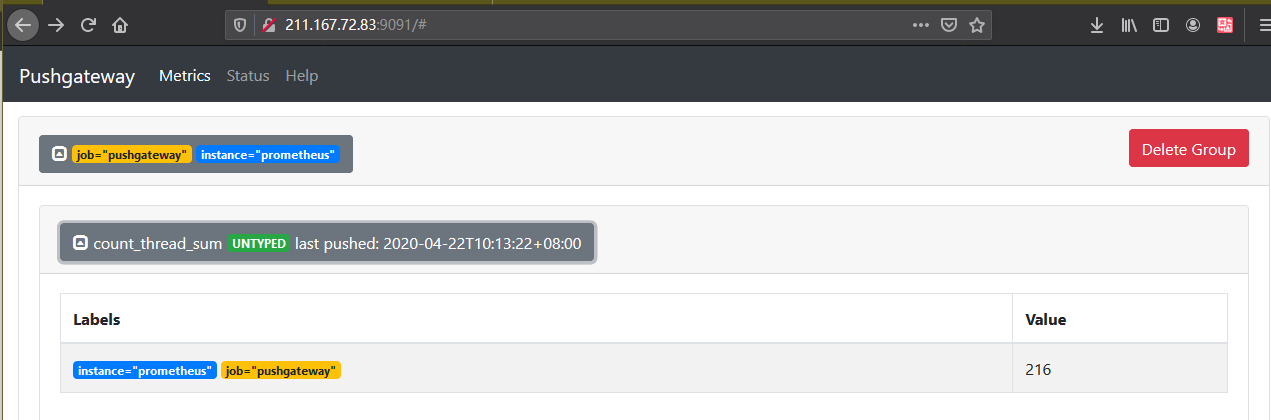 - 进入grafana页面,新建一个图表 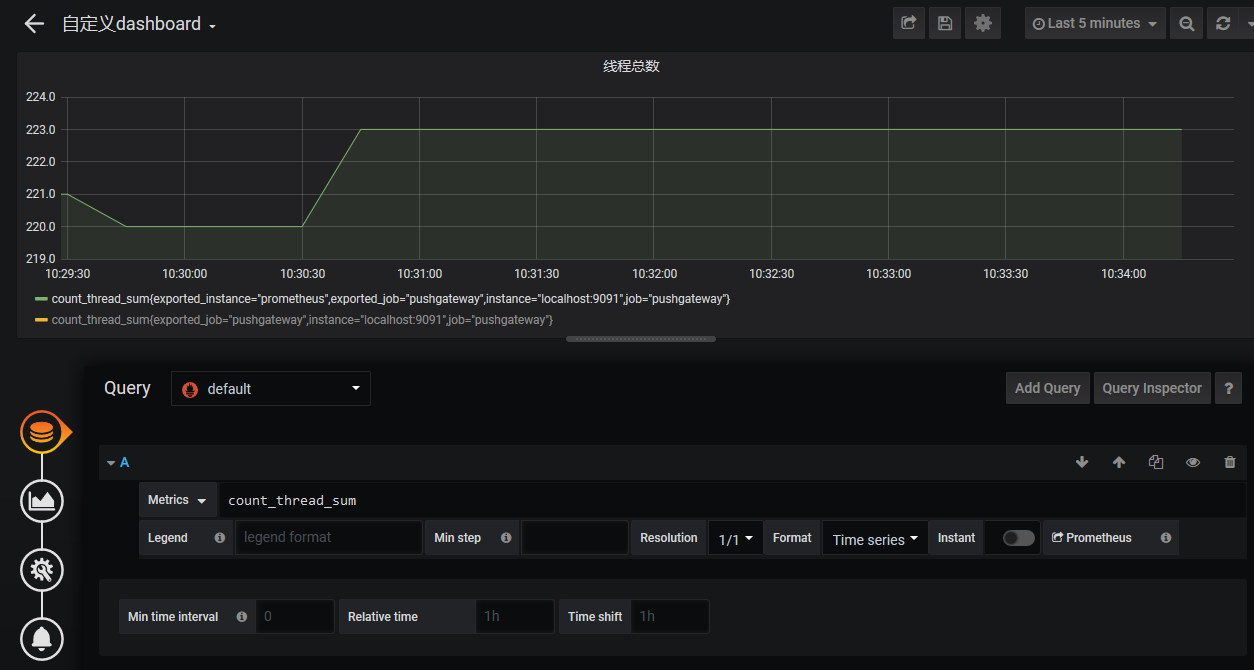 1. 监控每个进程资源使用情况
Nathan
2024年8月24日 15:08
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码