Kubernetes
一、基础知识
1. 概念和术语
2. Kubernetes特性
3. 集群组件
4. 抽象对象
5. 镜像加速下载
二、安装部署kubeadm
1. 基础环境准备
2. 安装runtime容器(Docker)
3. 安装runtime容器(Contained)
4. Containerd进阶使用
5. 部署kubernets集群
6. 部署calico网络组件
7. 部署NFS文件存储
8. 部署ingress-nginx代理
9. 部署helm包管理工具
10. 部署traefik代理
11. 部署dashboard管理面板(官方)
12. 部署kubesphere管理面板(推荐)
12. 部署metrics监控组件
13. 部署Prometheus监控
14. 部署elk日志收集
15. 部署Harbor私有镜像仓库
16. 部署minIO对象存储
17. 部署jenkins持续集成工具
三、kubectl命令
1. 命令格式
2.node操作常用命令
3. pod常用命令
4.控制器常用命令
5.service常用命令
6.存储常用命令
7.日常命令总结
8. kubectl常用命令
四、资源对象
1. K8S中的资源对象
2. yuml文件
3. Kuberbetes YAML 字段大全
4. 管理Namespace资源
5. 标签与标签选择器
6. Pod资源对象
7. Pod生命周期与探针
8. 资源需求与限制
9. Pod服务质量(优先级)
五、资源控制器
1. Pod控制器
2. ReplicaSet控制器
3. Deployment控制器
4. DaemonSet控制器
5. Job控制器
6. CronJob控制器
7. StatefulSet控制器
8. PDB中断预算
六、Service和Ingress
1. Service资源介绍
2. 服务发现
3. Service(ClusterIP)
4. Service(NodePort)
5. Service(LoadBalancer)
6. Service(ExternalName)
7. 自定义Endpoints
8. HeadlessService
9. Ingress资源
10. nginx-Ingress案例
七、Traefik
1. 知识点梳理
2. 简介
3. 部署与配置
4. 路由(IngressRoute)
5. 中间件(Middleware)
6. 服务(TraefikService)
7. 插件
8. traefikhub
9. 配置发现(Consul)
10. 配置发现(Etcd)
八、存储
1. 配置集合ConfigMap
6. downwardAPI存储卷
3. 临时存储emptyDir
2. 敏感信息Secret
5. 持久存储卷
4. 节点存储hostPath
7. 本地持久化存储localpv
九、rook
1. rook简介
2. ceph
3. rook部署
4. rbd块存储服务
5. cephfs共享文件存储
6. RGW对象存储服务
7. 维护rook存储
十、网络
1. 网络概述
2. 网络类型
3. flannel网络插件
4. 网络策略
5. 网络与策略实例
十一、安全
1. 安全上下文
2. 访问控制
3. 认证
4. 鉴权
5. 准入控制
6. 示例
十二、pod调度
1. 调度器概述
2. label标签调度
3. node亲和调度
4. pod亲和调度
5. 污点和容忍度
6. 固定节点调度
十三、系统扩展
1. 自定义资源类型(CRD)
2. 自定义控制器
十四、资源指标与HPA
1. 资源监控及资源指标
2. 监控组件安装
3. 资源指标及其应用
4. 自动弹性缩放
十五、helm
1. helm基础
2. helm安装
3. helm常用命令
4. HelmCharts
5. 自定义Charts
6. helm导出yaml文件
十六、k8s高可用部署
1. kubeadm高可用部署
2. 离线二进制部署k8s
3. 其他高可用部署方式
十七、日常维护
1. 修改节点pod个数上限
2. 集群证书过期更换
3. 更改证书有效期
4. k8s版本升级
5. 添加work节点
6. master节点启用pod调度
7. 集群以外节点控制k8s集群
8. 删除本地集群
9. 日常错误排查
10. 节点维护状态
11. kustomize多环境管理
12. ETCD节点故障修复
13. 集群hosts记录
14. 利用Velero对K8S集群备份还原与迁移
15. 解决K8s Namespace无法正常删除的问题
16. 删除含指定名称的所有资源
十八、k8s考题
1. 准备工作
2. 故障排除
3. 工作负载和调度
4. 服务和网络
5. 存储
6. 集群架构、安装和配置
本文档使用 MrDoc 发布
-
+
首页
1. kubeadm高可用部署
# 高可用架构方案 ## 高可用架构说明 | 核心组件 | 高可用模式 | 高可用实现方式 | | --- | --- | --- | | apiserver | 主备 | keepalived | | controller-manager | 主备 | leader election | | scheduler | 主备 | leader election | | etcd | 集群 | kubeadm | - apiserver 通过haproxy+keepalived实现高可用,当某个节点故障时触发keepalived vip 转移; - controller-manager k8s内部通过选举方式产生领导者(由--leader-elect 选型控制,默认为true),同一时刻集群内只有一个controller-manager组件运行; - scheduler k8s内部通过选举方式产生领导者(由--leader-elect 选型控制,默认为true),同一时刻集群内只有一个scheduler组件运行; - etcd 通过运行kubeadm方式自动创建集群来实现高可用,部署的节点数为奇数。如果剩余可用节点数量超过半数,集群可以几乎没有影响的正常工作(3节点方式最多容忍一台机器宕机) ## HAProxy+Keepalived方案 在以前我们在私有环境下创建 Kubernetes 集群时,我们需要准备一个硬件/软件的负载均衡器来创建多控制面集群,更多的情况下我们会选择使用 HAProxy + Keepalived 来实现这个功能。一般情况下我们会在k8s集群外创建2个负载均衡器的虚拟机,然后分配一个 VIP,然后使用 VIP 为负载均衡器提供服务,通过 VIP 将流量重定向到后端的某个 Kubernetes master节点上。<br />或者在所有Kubernetes master节点上部署HAProxy + Keepalived服务,实现故障切换。<br /> ## kube-vip方案 除了使用传统方式外,我们也可以通过kube-vip实现高可用。kube-vip 可以通过静态 pod 运行在控制平面节点上,这些 pod 通过ARP 对话来识别每个节点上的其他主机,所以需要在 hosts 文件中设置每个节点的 IP 地址,我们可以选择 BGP 或 ARP 来设置负载平衡器,这与 Metal LB 比较类似。在 ARP 模式下,会选出一个领导者,这个节点将继承虚拟 IP 并成为集群内负载均衡的 Leader,而在 BGP 模式下,所有节点都会通知 VIP 地址。<br />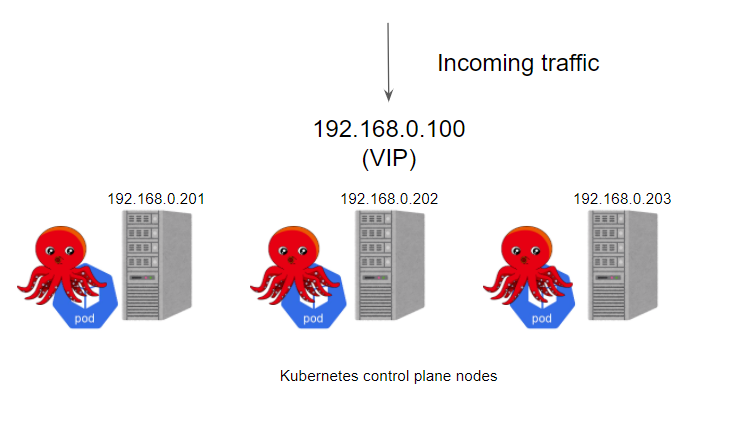 # kube-vip 架构 kube-vip 有许多功能设计选择提供高可用性或网络功能,作为VIP/负载平衡解决方案的一部分。 ## Cluster kube-vip 建立了一个多节点或多模块的集群来提供高可用性。在 ARP 模式下,会选出一个领导者,这个节点将继承虚拟 IP 并成为集群内负载均衡的领导者,而在 BGP 模式下,所有节点都会通知 VIP 地址。<br />当使用 ARP 或 layer2 时,它将使用领导者选举,当然也可以使用 raft 集群技术,但这种方法在很大程度上已经被领导者选举所取代,特别是在集群中运行时。 ## 虚拟IP 集群中的领导者将分配 vip,并将其绑定到配置中声明的选定接口上。当领导者改变时,它将首先撤销 vip,或者在失败的情况下,vip 将直接由下一个当选的领导者分配。<br />当 vip 从一个主机移动到另一个主机时,任何使用 vip 的主机将保留以前的 vip <-> MAC 地址映射,直到 ARP 过期(通常是30秒)并检索到一个新的 vip <-> MAC 映射,这可以通过使用无偿的 ARP 广播来优化。 ## ARP kube-vip可以被配置为广播一个无偿的 arp(可选),通常会立即通知所有本地主机 vip <-> MAC 地址映射已经改变。当 ARP 广播被接收时,故障转移通常在几秒钟内完成。 # 集群规划 ## 软件版本 操作系统版本:Rocky Linux release 8.8<br />内核版本:4.18.0-477.21.1.el8_8.x86_64<br />kubernetes版本:1.27.6<br />containerd版本:1.6.22<br />kube-vip版本:0.6.0 ## 主机IP规划 | 主机名 | ip | 主机配置 | 用途 | | --- | --- | --- | --- | | master1 | 192.168.10.151 | 2C2G | control-plane | | master2 | 192.168.10.152 | 2C2G | control-plane | | master3 | 192.168.10.153 | 2C2G | control-plane | | work1 | 192.168.10.154 | 2C2G | work | | work2 | 192.168.10.155 | 2C2G | work | | work3 | 192.168.10.156 | 2C2G | work | | VIP | 192.168.10.150 | / | 虚拟IP在控制节点上浮动 | | tiaoban | 192.168.10.100 | 2C2G | 客户端,连接管理K8S集群 | # 基础环境与软件准备 > 以下操作在所有节点都执行 ## 修改主机名与hosts文件 ```bash hostnamectl set-hostname master1 cat > /etc/hosts << EOF 192.168.10.151 master1 192.168.10.152 master2 192.168.10.153 master3 192.168.10.154 work1 192.168.10.155 work2 192.168.10.156 work3 EOF ``` ## 验证mac地址uuid 保证各节点mac和uuid唯一,防止克隆主机出现网络异常问题 ```bash cat /sys/class/net/ens33/address cat /sys/class/dmi/id/product_uuid ``` ## 配置时间同步 ```bash dnf -y install chrony systemctl start chronyd systemctl enable chronyd timedatectl set-timezone Asia/Shanghai chronyc sourcestats -v date ``` > 也可以在内网环境其中一台主机启动chronyd服务,其他主机配置chronyd服务地址,参考文档:[https://www.cuiliangblog.cn/detail/section/31516177](https://www.cuiliangblog.cn/detail/section/31516177) ## 关闭防火墙和selinux ```bash systemctl stop firewalld.service systemctl disable firewalld setenforce 0 sed -i 's/enforcing/disabled/g' /etc/selinux/config grep SELINUX= /etc/selinux/config ``` ## 关闭swap分区 ```bash swapoff -a sed -i '/ swap / s/^(.*)$/#\1/g' /etc/fstab ``` ## 修改内核相关参数 最大限度使用物理内存,bridge 设备在二层转发时也去调用 iptables 配置的三层规则,开启数据包转发。 ```bash cat > /etc/sysctl.d/kubernetes.conf << EOF vm.swappiness = 0 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/kubernetes.conf ``` ## 配置yum源 配置阿里源 ```bash cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF ``` 如果阿里源异常,可切换配置清华源 ```bash cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=kubernetes baseurl=https://mirrors.tuna.tsinghua.edu.cn/kubernetes/yum/repos/kubernetes-el7-$basearch enabled=1 EOF ``` ## 配置ipvs模块功能 ```bash dnf -y install ipset ipvsadm cat > /etc/sysctl.d/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack modprobe -- br_netfilter EOF chmod 755 /etc/sysctl.d/ipvs.modules && bash /etc/sysctl.d/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack ip_vs_sh 20480 0 ip_vs_wrr 16384 0 ip_vs_rr 16384 0 ip_vs 180224 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack_netlink 53248 0 nf_conntrack 176128 5 xt_conntrack,nf_nat,nf_conntrack_netlink,xt_MASQUERADE,ip_vs nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs nf_defrag_ipv4 16384 1 nf_conntrack nfnetlink 20480 4 nft_compat,nf_conntrack_netlink,nf_tables libcrc32c 16384 5 nf_conntrack,nf_nat,nf_tables,xfs,ip_vs # 添加开机自动加载模块 echo "/etc/sysctl.d/ipvs.modules" >> /etc/rc.local chmod +x /etc/rc.d/rc.local # 启用网桥过滤器模块 echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables echo 1 > /proc/sys/net/ipv4/ip_forward ``` ## 安装命令自动补全工具 ```bash dnf -y install bash-completion source /etc/profile.d/bash_completion.sh ``` ## container安装 ### 安装软件包 ```bash # 安装依赖 dnf install -y yum-utils device-mapper-persistent-data lvm2 # 添加yum源 dnf config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 查看可安装的containerd版本 dnf list containerd.io.x86_64 --showduplicates | sort -r # 安装1.6.22版本containerd dnf install -y containerd.io-1.6.22-3.1.el8.x86_64 # 查看版本信息 containerd -v ``` ### 配置container **生成默认配置文件** ```bash containerd config default > /etc/containerd/config.toml ``` **替换镜像源**<br />由于国内环境原因我们需要将 sandbox_image 镜像源设置为阿里云google_containers镜像源。把sandbox_image = "k8s.gcr.io/pause:3.6"修改为:sandbox_image=“registry.aliyuncs.com/google_containers/pause:3.6” ``` sed -i 's/sandbox_image\ =.*/sandbox_image\ =\ "registry.aliyuncs.com\/google_containers\/pause:3.6"/g' /etc/containerd/config.toml|grep sandbox_image ``` **配置cgroup驱动器**<br />在 Linux 上,控制组(CGroup)用于限制分配给进程的资源。<br />kubelet 和底层容器运行时都需要对接控制组 为 Pod 和容器管理资源 ,如 CPU、内存这类资源设置请求和限制。 若要对接控制组(CGroup),kubelet 和容器运行时需要使用一个 cgroup 驱动。 关键的一点是 kubelet 和容器运行时需使用相同的 cgroup 驱动并且采用相同的配置。 ``` sed -i 's/SystemdCgroup\ =\ false/SystemdCgroup\ =\ true/g' /etc/containerd/config.toml ``` **配置国内镜像加速地址** ```bash # 修改container配置,指定registry配置从文件读取 vim /etc/containerd/config.toml [plugins."io.containerd.grpc.v1.cri".registry] config_path = "/etc/containerd/certs.d" # 创建配置文件目录 mkdir -p /etc/containerd/certs.d/docker.io # 新增加速配置 cat > /etc/containerd/certs.d/docker.io/hosts.toml << EOF server = "https://docker.io" [host."https://o2j0mc5x.mirror.aliyuncs.com"] capabilities = ["pull", "resolve"] server = "https://k8s.gcr.io" [host."https://gcr.mirrors.ustc.edu.cn/google-containers/"] capabilities = ["pull", "resolve"] server = "https://quay.io" [host."https://mirror.ccs.tencentyun.com"] capabilities = ["pull", "resolve"] EOF ``` ### 启动 container服务 ```bash systemctl enable containerd --now ``` ### 安装配置crictl crictl 是 CRI 兼容的容器运行时命令行接口,和containerd无关,由Kubernetes提供,可以使用它来检查和调试 k8s 节点上的容器运行时和应用程序。<br />下载地址:https://github.com/kubernetes-sigs/cri-tools/releases ```bash # 下载 wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.27.1/crictl-v1.27.1-linux-amd64.tar.gz # 解压 tar -zxvf crictl-v1.27.1-linux-amd64.tar.gz -C /usr/local/bin # 配置 cat > /etc/crictl.yaml << EOF runtime-endpoint: "unix:///run/containerd/containerd.sock" image-endpoint: "unix:///run/containerd/containerd.sock" timeout: 0 debug: false pull-image-on-create: false disable-pull-on-run: false EOF # 验证 crictl version ``` ### 安装配置nerdctl(建议) containerd虽然可直接提供给终端用户直接使用,也提供了命令行工具(ctr),但并不是很友好,所以nerdctl应运而生,它也是containerd的命令行工具,支持docker cli关于容器生命周期管理的所有命令,并且支持docker compose (nerdctl compose up)<br />下载地址:[https://github.com/containerd/nerdctl/releases](https://github.com/containerd/nerdctl/releases) ```bash # 下载 wget https://github.com/containerd/nerdctl/releases/download/v1.5.0/nerdctl-1.5.0-linux-amd64.tar.gz # 解压 tar -zxvf nerdctl-1.5.0-linux-amd64.tar.gz # 复制文件 cp nerdctl /usr/bin/ # 配置 nerdctl 参数自动补齐 echo 'source <(nerdctl completion bash)' >> /etc/profile source /etc/profile # 验证 nerdctl -v ``` ## 安装k8s软件包并配置 - 安装软件包 ```bash yum install -y kubelet kubeadm kubectl # 默认安装最新版本,如果需要安装老版本,使用如下命令 yum list kubeadm --showduplicates | sort -r yum install -y kubelet-1.27.6 kubeadm-1.27.6 kubectl-1.27.6 ``` - 指定kubelet的容器运行时并启动。 ```bash crictl config runtime-endpoint unix:///run/containerd/containerd.sock systemctl enable kubelet --now ``` - kubectl命令补全 ```bash echo "source <(kubectl completion bash)" >> ~/.bash_profile source ~/.bash_profile ``` # kube-vip部署配置 > 以下操作在master1节点执行 ## 准备工作 我们使用的vip是192.168.10.150<br />网卡名称是ens160 <br />kube-vip使用arp模式<br />参考文档:[https://kube-vip.io/docs/installation/static/#kube-vip-as-ha-load-balancer-or-both](https://kube-vip.io/docs/installation/static/#kube-vip-as-ha-load-balancer-or-both) ```bash [root@master1 ~]# mkdir -p /etc/kubernetes/manifests [root@master1 ~]# export VIP=192.168.10.150 [root@master1 ~]# export INTERFACE=ens160 [root@master1 ~]# export KVVERSION=v0.6.0 ``` ## 生成配置文件 获取 kube-vip 的 docker 镜像,并在 /etc/kuberentes/manifests 中设置静态 pod 的 yaml 资源清单文件,这样 Kubernetes 就会自动在每个控制平面节点上部署 kube-vip 的 pod 了。 ```yaml [root@master1 ~]# alias kube-vip="ctr image pull ghcr.io/kube-vip/kube-vip:$KVVERSION; ctr run --rm --net-host ghcr.io/kube-vip/kube-vip:$KVVERSION vip /kube-vip" [root@master1 ~]# kube-vip manifest pod \ --interface $INTERFACE \ --address $VIP \ --controlplane \ --services \ --arp \ --leaderElection | tee /etc/kubernetes/manifests/kube-vip.yaml # 生成文件如下所示: apiVersion: v1 kind: Pod metadata: creationTimestamp: null name: kube-vip namespace: kube-system spec: containers: - args: - manager env: - name: vip_arp value: "true" - name: port value: "6443" - name: vip_interface value: ens160 - name: vip_cidr value: "32" - name: cp_enable value: "true" - name: cp_namespace value: kube-system - name: vip_ddns value: "false" - name: svc_enable value: "true" - name: vip_leaderelection value: "true" - name: vip_leaseduration value: "5" - name: vip_renewdeadline value: "3" - name: vip_retryperiod value: "1" - name: vip_address value: 192.168.10.150 - name: prometheus_server value: :2112 image: ghcr.io/kube-vip/kube-vip:v0.6.0 imagePullPolicy: Always name: kube-vip resources: {} securityContext: capabilities: add: - NET_ADMIN - NET_RAW volumeMounts: - mountPath: /etc/kubernetes/admin.conf name: kubeconfig hostAliases: - hostnames: - kubernetes ip: 127.0.0.1 hostNetwork: true volumes: - hostPath: path: /etc/kubernetes/admin.conf name: kubeconfig status: {} ``` 当执行完kubeadm init后,kubelet会去加载这里面的yaml创建kube-vip容器。 ## 拷贝至其他master节点 所有master节点都需要部署一个kube-vip,我们只需要将yaml文件存放在/etc/kubernetes/manifests/目录下,kubelet启动时会自动加载资源清单并创建pod。 ```bash [root@master1 ~]# scp /etc/kubernetes/manifests/kube-vip.yaml master2:/etc/kubernetes/manifests/kube-vip.yaml [root@master1 ~]# scp /etc/kubernetes/manifests/kube-vip.yaml master3:/etc/kubernetes/manifests/kube-vip.yaml ``` # 初始化master节点 > 以下操作在master1节点执行 ## 配置集群参数 获取默认的初始化参数文件 ```yaml [root@master1 ~]# kubeadm config print init-defaults > kubeadm-conf.yaml ``` 修改配置文件 ```yaml [root@master1 ~]# cat kubeadm-conf.yaml apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.10.151 # 指定当前master1节点IP bindPort: 6443 nodeRegistration: criSocket: unix:///run/containerd/containerd.sock # 使用containerd的socket地址 imagePullPolicy: IfNotPresent name: master1 # 节点主机名 taints: null --- apiServer: extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s certSANs: # 添加其他master节点的相关信息 - 127.0.0.1 - master1 - master2 - master3 - 192.168.10.151 - 192.168.10.152 - 192.168.10.153 apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers # 阿里云镜像 kind: ClusterConfiguration kubernetesVersion: 1.27.6 # k8s版本 controlPlaneEndpoint: 192.168.10.150:6443 # 设置控制平面Endpoint地址 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 podSubnet: 10.244.0.0/16 # 指定 pod 子网 scheduler: {} --- # 指定kube-proxy基于ipvs模式 apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs --- apiVersion: kubelet.config.k8s.io/v1beta1 authentication: anonymous: enabled: false webhook: cacheTTL: 0s enabled: true x509: clientCAFile: /etc/kubernetes/pki/ca.crt authorization: mode: Webhook webhook: cacheAuthorizedTTL: 0s cacheUnauthorizedTTL: 0s cgroupDriver: systemd # 指定cgroup驱动器为systemd模式 clusterDNS: - 10.96.0.10 clusterDomain: cluster.local cpuManagerReconcilePeriod: 0s evictionPressureTransitionPeriod: 0s fileCheckFrequency: 0s healthzBindAddress: 127.0.0.1 healthzPort: 10248 httpCheckFrequency: 0s imageMinimumGCAge: 0s kind: KubeletConfiguration logging: {} memorySwap: {} nodeStatusReportFrequency: 0s nodeStatusUpdateFrequency: 0s rotateCertificates: true runtimeRequestTimeout: 0s shutdownGracePeriod: 0s shutdownGracePeriodCriticalPods: 0s staticPodPath: /etc/kubernetes/manifests streamingConnectionIdleTimeout: 0s syncFrequency: 0s volumeStatsAggPeriod: 0s ``` 对于上面的资源清单的文档比较杂,要想完整了解上面的资源对象对应的属性,可以查看对应的 godoc 文档,地址: [https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta3](https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta3) ## 拉取镜像 将master1节点的kubeadm-conf.yaml复制到其他master节点,所有master节点都提前执行 ```bash [root@master1 ~]# kubeadm config images pull --config kubeadm-conf.yaml [config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.27.6 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.27.6 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.27.6 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.27.6 [config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.9 [config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.7-0 [config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.10.1 # CRI sandbox(pause) image默认使用registry.k8s.io/pause:3.6,由于网络原因无法拉取,直接改为阿里镜像标签即可。 [root@master1 ~]# nerdctl -n k8s.io tag registry.aliyuncs.com/google_containers/pause:3.9 registry.k8s.io/pause:3.6 ``` ## 集群初始化 ```bash [root@master1 ~]# kubeadm init --upload-certs --config=kubeadm-conf.yaml Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.10.150:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4f8a53db87e99a4f3e8512169b7269ef2e28779e4602c0c3df898c645973c88c \ --control-plane --certificate-key efde545c8ea984be7ce9449ea1e77eb44659f1708001be512b7e01f70cf568b7 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.10.150:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4f8a53db87e99a4f3e8512169b7269ef2e28779e4602c0c3df898c645973c88c ``` - --upload-certs 标志用来将在所有控制平面实例之间的共享证书上传到集群。然后根据安装提示拷贝 kubeconfig 文件 - 如果配置问题导致集群初始化失败,可重置集群再次初始化: ```bash [root@master1 ~]# kubeadm reset [root@master1 ~]# ipvsadm --clear [root@master1 ~]# rm -rf $HOME/.kube/config ``` ## 根据提示配置环境变量 ```bash [root@master1 ~]# mkdir -p $HOME/.kube [root@master1 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master1 ~]# chown $(id -u):$(id -g) $HOME/.kube/config # 配置kubectl命令自动补全 [root@master1 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile [root@tiaoban ~]# source ~/.bash_profile ``` ## 安装flannel网络 - 下载资源清单配置文件 ```bash [root@master1 ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml ``` - 创建资源 ```bash [root@master1 ~]# kubectl apply -f kube-flannel.yml ``` - 如果镜像不能正常拉取,所有节点需提前导入镜像,并修改yaml文件镜像拉取策略 ```bash imagePullPolicy: IfNotPresent ``` - 镜像导入与查询 ```bash [root@work3 ~]# ctr -n=k8s.io image import flannel.tar unpacking docker.io/flannel/flannel:v0.22.1 (sha256:0b78f714708e837ae667c204cc918649ebcf2441b1d18ebde9a6564254932ee5)...done [root@work3 ~]# crictl images IMAGE TAG IMAGE ID SIZE docker.io/flannel/flannel-cni-plugin v1.2.0 a55d1bad692b7 8.32MB ``` # 其他节点加入集群 ## master节点加入集群 另外两个节点 master2 和 master3 都执行上面的 join 命令,上面的命令中的 --control-plane 就是通知 kubeadm join 创建一个新的控制平面,--certificate-key 会从集群中的 kubeadm-certs Secret 下载控制平面证书并使用给定的密钥进行解密。 ```bash # 以master2节点为例 [root@master2 ~]# kubeadm join 192.168.10.150:6443 --token abcdef.0123456789abcdef \ > --discovery-token-ca-cert-hash sha256:4f8a53db87e99a4f3e8512169b7269ef2e28779e4602c0c3df898c645973c88c \ > --control-plane --certificate-key efde545c8ea984be7ce9449ea1e77eb44659f1708001be512b7e01f70cf568b7 # 然后根据提示配置环境变量 [root@master2 ~]# mkdir -p $HOME/.kube [root@master2 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master2 ~]# chown $(id -u):$(id -g) $HOME/.kube/config ``` ## work节点加入集群 ```bash kubeadm join 192.168.10.150:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:4f8a53db87e99a4f3e8512169b7269ef2e28779e4602c0c3df898c645973c88c ``` ## client配置 ```bash # 安装指定版本的kubelet [root@tiaoban ~]# yum install -y kubectl-1.27.6 # 拷贝集群认证文件并配置环境变量 [root@tiaoban ~]# mkdir -p /etc/kubernetes [root@tiaoban ~]# scp master1:/etc/kubernetes/admin.conf /etc/kubernetes/ [root@tiaoban ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile [root@tiaoban ~]# source ~/.bash_profile ``` # 集群验证 > 以下操作在tiaoban节点执行 ## 查看节点信息 ```bash [root@tiaoban ~]# kubectl get node NAME STATUS ROLES AGE VERSION master1 Ready control-plane 18m v1.27.6 master2 Ready control-plane 12m7s v1.27.6 master3 Ready control-plane 13m6s v1.27.6 work1 Ready <none> 8m25s v1.27.6 work2 Ready <none> 8m21s v1.27.6 work3 Ready <none> 8m17s v1.27.6 ``` ## 查看pod信息 ```bash [root@master1 ~]# kubectl get pod -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel kube-flannel-ds-2nqk5 1/1 Running 0 134s 192.168.10.151 master1 <none> <none> kube-flannel kube-flannel-ds-c87jk 1/1 Running 0 134s 192.168.10.155 work2 <none> <none> kube-flannel kube-flannel-ds-hnps5 1/1 Running 0 134s 192.168.10.154 work1 <none> <none> kube-flannel kube-flannel-ds-jphgx 1/1 Running 0 154s 192.168.10.153 master3 <none> <none> kube-flannel kube-flannel-ds-lxpsp 1/1 Running 0 134s 192.168.10.156 work3 <none> <none> kube-flannel kube-flannel-ds-rx5kf 1/1 Running 0 134s 192.168.10.152 master2 <none> <none> kube-system coredns-7bdc4cb885-cjbbx 1/1 Running 0 14m 10.244.5.3 work1 <none> <none> kube-system coredns-7bdc4cb885-sgsns 1/1 Running 0 14m 10.244.5.2 work1 <none> <none> kube-system etcd-master1 1/1 Running 1 14m 192.168.10.151 master1 <none> <none> kube-system etcd-master2 1/1 Running 0 15m 192.168.10.152 master2 <none> <none> kube-system etcd-master3 1/1 Running 0 14m 192.168.10.153 master3 <none> <none> kube-system kube-apiserver-master1 1/1 Running 1 14m 192.168.10.151 master1 <none> <none> kube-system kube-apiserver-master2 1/1 Running 0 15m 192.168.10.152 master2 <none> <none> kube-system kube-apiserver-master3 1/1 Running 2 (154m ago) 14m 192.168.10.153 master3 <none> <none> kube-system kube-controller-manager-master1 1/1 Running 3 (40m ago) 14m 192.168.10.151 master1 <none> <none> kube-system kube-controller-manager-master2 1/1 Running 0 15m 192.168.10.152 master2 <none> <none> kube-system kube-controller-manager-master3 1/1 Running 0 14m 192.168.10.153 master3 <none> <none> kube-system kube-proxy-9jsq7 1/1 Running 0 18m 192.168.10.155 work2 <none> <none> kube-system kube-proxy-cpb5n 1/1 Running 0 14m 192.168.10.151 master1 <none> <none> kube-system kube-proxy-dm2rm 1/1 Running 0 14m 192.168.10.153 master3 <none> <none> kube-system kube-proxy-g26c4 1/1 Running 0 15m 192.168.10.152 master2 <none> <none> kube-system kube-proxy-jkhnj 1/1 Running 0 18m 192.168.10.156 work3 <none> <none> kube-system kube-proxy-x29d9 1/1 Running 0 18m 192.168.10.154 work1 <none> <none> kube-system kube-scheduler-master1 1/1 Running 3 (39m ago) 14m 192.168.10.151 master1 <none> <none> kube-system kube-scheduler-master2 1/1 Running 0 15m 192.168.10.152 master2 <none> <none> kube-system kube-scheduler-master3 1/1 Running 0 14m 192.168.10.153 master3 <none> <none> kube-system kube-vip-master1 1/1 Running 0 1m 192.168.10.151 master1 <none> <none> kube-system kube-vip-master2 1/1 Running 1 (38m ago) 15m 192.168.10.152 master2 <none> <none> kube-system kube-vip-master3 1/1 Running 0 14m 192.168.10.153 master3 <none> <none> ``` # 集群高可用测试 ## 组件所在节点查看 查看VIP所在节点(当前位于master2) ```bash [root@tiaoban ~]# ansible k8s-ha -m shell -a "ip a | grep 192.168.10.150" [WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details work2 | FAILED | rc=1 >> non-zero return code master2 | CHANGED | rc=0 >> inet 192.168.10.150/32 scope global ens160 work1 | FAILED | rc=1 >> non-zero return code master1 | FAILED | rc=1 >> non-zero return code master3 | FAILED | rc=1 >> non-zero return code work3 | FAILED | rc=1 >> non-zero return code ``` 查看其他组件所在节点(controller-manager位于master1,scheduler 位于master3) ```bash [root@tiaoban ~]# kubectl get leases -n kube-system NAME HOLDER AGE apiserver-bqv2ezepcsovu7bfu7lvbrdg2m apiserver-bqv2ezepcsovu7bfu7lvbrdg2m_c3892ab2-71ee-40f4-be66-4f65c664f568 175m apiserver-bskcrn2i4gf5c5gco6huepssle apiserver-bskcrn2i4gf5c5gco6huepssle_00e69eb5-4df9-4c3d-87e0-2eb54d7d93c4 3h6m apiserver-s5dbgrswajhxxnkoaowmosesjm apiserver-s5dbgrswajhxxnkoaowmosesjm_3665e3ce-dc72-440d-ba7a-ff08f9c71b6a 176m kube-controller-manager master1_08adefe3-56c0-4c87-94b7-9adda172eaf3 3h6m kube-scheduler master3_59611769-b42d-459a-aa45-6ccf535d793f 3h6m plndr-cp-lock master3 176m plndr-svcs-lock master1 176m ``` 创建deployment和svc,模拟生产业务 ```bash # 新建资源清单 [root@tiaoban k8s]# cat > demo.yaml << EOF apiVersion: apps/v1 kind: Deployment metadata: name: myapp spec: replicas: 3 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: containers: - name: myapp image: ikubernetes/myapp:v1 ports: - containerPort: 80 name: http --- apiVersion: v1 kind: Service metadata: name: myapp-svc spec: selector: app: myapp type: NodePort ports: - port: 80 targetPort: 80 EOF # 创建资源 [root@tiaoban k8s]# kubectl apply -f demo.yaml deployment.apps/myapp created service/myapp-svc created # 查看资源信息 [root@tiaoban k8s]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-64b6b8fbcd-jm5q2 1/1 Running 0 101s 10.244.3.2 work3 <none> <none> myapp-64b6b8fbcd-qqjsd 1/1 Running 0 101s 10.244.4.2 work2 <none> <none> myapp-64b6b8fbcd-tsmwx 1/1 Running 0 101s 10.244.5.6 work1 <none> <none> [root@tiaoban k8s]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3h17m myapp-svc NodePort 10.110.186.236 <none> 80:30380/TCP 5m6s # 访问测试 [root@tiaoban k8s]# curl 192.168.10.150:30380 Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> ``` ## 宕机一台控制节点 将VIP所在的master2节点关机,模拟宕机 ```bash [root@master3 ~]# init 0 ``` 各组件信息查看 ```bash # VIP位于master1 [root@tiaoban k8s]# ansible k8s-ha -m shell -a "ip a | grep 192.168.10.150" [WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details [WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details master2 | UNREACHABLE! => { "changed": false, "msg": "Failed to connect to the host via ssh: ssh: connect to host master2 port 22: Connection refused", "unreachable": true } work2 | FAILED | rc=1 >> non-zero return code work3 | FAILED | rc=1 >> non-zero return code work1 | FAILED | rc=1 >> non-zero return code master3 | FAILED | rc=1 >> non-zero return code master1 | CHANGED | rc=0 >> inet 192.168.10.150/32 scope global ens160 # controller-manager位于master1 scheduler位于master3 [root@tiaoban k8s]# kubectl get leases -n kube-system NAME HOLDER AGE apiserver-bqv2ezepcsovu7bfu7lvbrdg2m apiserver-bqv2ezepcsovu7bfu7lvbrdg2m_c3892ab2-71ee-40f4-be66-4f65c664f568 3h19m apiserver-bskcrn2i4gf5c5gco6huepssle apiserver-bskcrn2i4gf5c5gco6huepssle_00e69eb5-4df9-4c3d-87e0-2eb54d7d93c4 3h30m apiserver-s5dbgrswajhxxnkoaowmosesjm apiserver-s5dbgrswajhxxnkoaowmosesjm_3665e3ce-dc72-440d-ba7a-ff08f9c71b6a 3h20m kube-controller-manager master1_fd5b1081-93e2-4be8-8eb8-8719a70b606a 3h29m kube-scheduler master1_2b4c98a1-8d8c-4bb3-a3c4-58793022180a 3h29m plndr-cp-lock master3 3h20m plndr-svcs-lock master1 3h20m ``` 集群节点信息查看 ```bash [root@tiaoban k8s]# kubectl get node NAME STATUS ROLES AGE VERSION master1 Ready control-plane 3h31m v1.27.6 master2 NotReady control-plane 3h22m v1.27.6 master3 Ready control-plane 3h21m v1.27.6 work1 Ready <none> 3h14m v1.27.6 work2 Ready <none> 3h14m v1.27.6 work3 Ready <none> 3h14m v1.27.6 ``` 业务访问测试 ```bash [root@tiaoban k8s]# curl 192.168.10.150:30380 Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> ``` 结论:当有一个master节点宕机时,VIP会发生漂移,集群各项功能不受影响。
Nathan
2024年6月22日 12:48
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码