Nginx服务
对非同源地址的nginx配置要求
http同端口访问http跳转https(497错误)
关于Nginx 的 location 匹配规则总结
Nginx+LUA+Redis实现token访问鉴权
Nginx推荐日志配置格式
Nginx正确代理 SSE 与 WebSocket
Nginx实现后端Server域名动态解析
Nginx反向代理跨域问题
浏览器报错ERR_CONTENT_LENGTH_MISMATCH
Nginx常见HTTP Code错误排查
使用acme.sh部署证书至Nginx
Nginx在普通用户下使用特权端口 (443端口)
Nginx配置自定义状态页
try_files和alias的组合使用
Nginx中301重定向导致端口丢失
本文档使用 MrDoc 发布
-
+
首页
关于Nginx 的 location 匹配规则总结
## 前言 本次实践的环境: 系统: CentOS 7 Nginx 版本: 1.18.0 ## location 匹配的变量 Nginx 的 location 规则匹配的变量是 $uri, 所以不用管后面的参数 $query_string (或者 $args) ## location 匹配的种类 格式主要是这个: ``` location [空格 | = | ~ | ~* | ^~ | @ ] /uri/ { ... } ``` 上面分为三部分: - 最前面的字符 (location modifier) 匹配规则 - 后面 uri 的匹配规则 (location match) - 大括号内的路由转发 ## location modifier 格式: ``` [空格 | = | ~ | ~* | ^~ | @ ] ``` | 字符 | 解释 | | --- | --- | |空格|如果直接是一个空格,那就是不写 location modifier ,Nginx 仍然能去匹配 pattern 。这种情况下,匹配那些以指定的 patern 开头的 URI,注意这里的 URI 只能是普通字符串,不能使用正则表达式。| |=|表示精确匹配,如果找到,立即停止搜索并立即处理此请求。| |~|表示执行一个正则匹配,区分大小写匹配| |~*|表示执行一个正则匹配,不区分大小写匹配, 注意,如果是运行 Nginx server 的系统本身对大小写不敏感,比如 Windows ,那么 ~* 和 ~ 这两个表现是一样的| |^~|即表示只匹配普通字符(跟空格类似,但是它优先级比空格高)。使用前缀匹配,^表示“非”,即不查询正则表达式。如果匹配成功,并且所匹配的字符串是最长的, 则不再匹配其他location。| |@|用于定义一个 Location块,且该块不能被外部Client 所访问,只能被Nginx内部配置指令所访问,比如try_files 或 error_page| ## location modifier 的匹配顺序 Nginx官方wiki说明文档[[1]][01] 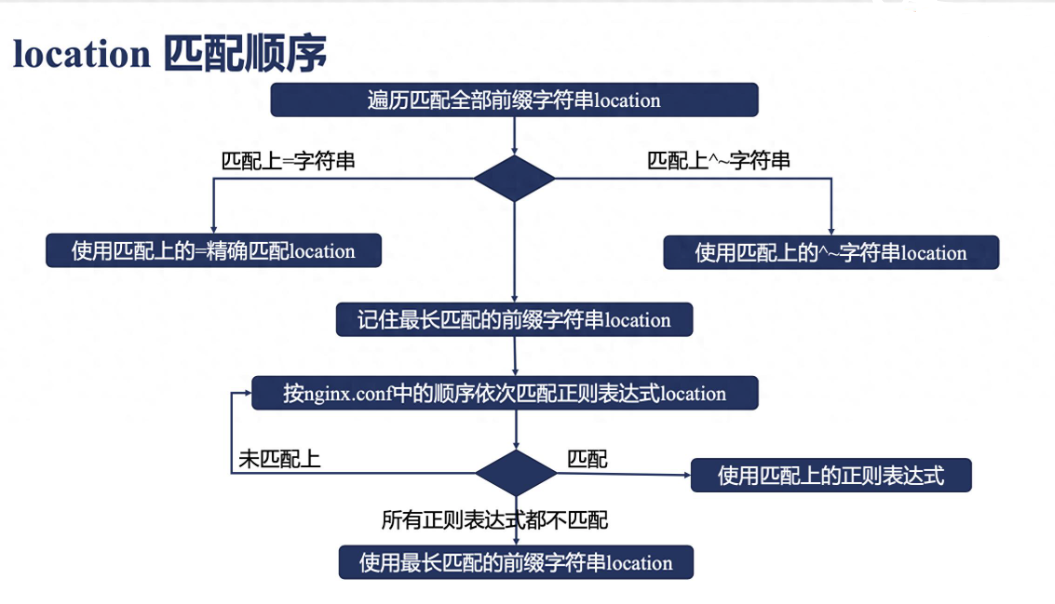 优先级的步骤如下: 1. 优先查找精确匹配,精确匹配 (=) 的 location 如果匹配请求 URI 的话,此 location 被马上使用,匹配过程结束。 2. 接下来进行字符串匹配(空格 和 \~^), 找到匹配最长的那个,如果发现匹配最长的那个是 ^~ 前缀, 那么也停止搜索并且马上使用,匹配过程结束。 否则继续往下走。 3. 如果字符串匹配没有,或者匹配的最长字符串不是 ^~ 前缀 (比如是空格匹配),那么就继续搜索正则表达式匹配, 这时候就根据在配置文件定义的顺序,取最上面的配置(正则匹配跟匹配长度没关系,只跟位置有关系,只取顺序最上面的匹配) 4. 如果第三步找到了,那么就用第三步的匹配,否则就用第二步的匹配 (字符匹配最长的空格匹配) 总结顺序如下 ``` 精确匹配 > 字符串匹配( 长 > 短 [ 注: ^~ 匹配则停止匹配 ]) > 正则匹配( 上 > 下 ) ``` 换成符号的优先级: ``` [=] > [^~] > [~/~*] > [空格] ``` 注意说明事项如下: 1. 常规字符串匹配类型。是按前缀匹配(从根开始)。 而正则匹配是包含匹配,只要包含就可以匹配 2. ~ 和 ~* 的优先级一样,取决于在配置文件中的位置,最上面的为主,跟匹配的字符串长度没关系,所以在写的时候,应该越精准的要放在越前面才对 3. 空格匹配和 ^~ 都是字符串匹配,所以如果两个后面的匹配字符串一样,是会报错的,因为 nginx 会认为两者的匹配规则一致,所以会有冲突 4. ^~, =, ~, ~* 这些修饰符和后面的 URI 字符串中间可以不使用空格隔开(大部分都是用空格隔开)。但是 @ 修饰符必须和 URI 字符串直接连接。 ------------ ## location match [uri] 根据需要匹配的 path 路径,根据前面的符号,这里可以填写精确到 path 路径,也可以填正则表达式,Nginx 用的是 PCRE正则表达式语法,下表是在PCRE中元字符及其在正则表达式上下文中的行为的一个完整列表: | 字符 | 描述 | | --- | --- | |\\|将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,\\\\n 匹配 \\n。\\n 匹配换行符。序列 \\\\ 匹配 \\ , 而 \\( 则匹配 (。即相当于多种编程语言中都有的转义字符的概念。|| |^|匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^也匹配\\n 或 \\r 之后的位置。| |$|匹配输入字符串的结束位置。如果设置了 RegExp 对象的 Multiline 属性,$ 也匹配\\n 或 \\r 之前的位置。| |*|匹配前面的子表达式零次或多次。例如,zo* 能匹配 z 以及zoo。 * 等价于 {0,}。| |+|匹配前面的子表达式一次或多次。例如,zo+ 能匹配 zo 以及 zoo,但不能匹配 z。+ 等价于 {1,}。| |?|匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 does 或 do。? 等价于 {0,1}。| |{n}|n 是一个非负整数。匹配确定的n次。例如,o{2} 不能匹配 Bob 中的 o,但是能匹配 food 中的两个o。| |{n,}|n 是一个非负整数。至少匹配n次。例如,o{2,} 不能匹配 Bob 中的 o,但能匹配 foooood 中的所有o。o{1,} 等价于 o+ 。o{0,} 则等价于 o*。| |{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,o{1,3} 将匹配 fooooood 中的前三个o。o{0,1} 等价于o?。 请注意在逗号和两个数之间不能有空格。| |?|当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串oooo,o+? 将匹配单个 o,而 o+ 将匹配所有 o。| |.|匹配除\\n和\\r之外的任何单个字符。要匹配包括\\n和\\r在内的任何字符,请使用像[\\s\\S]的模式。| |(pattern)|匹配pattern并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在 VBScript 中使用 SMatches 集合,在JScript中则使用 0…0…0…9 属性。要匹配圆括号字符,请使用\\( 或 \\)。| |(?:pattern)|匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符 "(|)" 来组合一个模式的各个部分是很有用。例如"industr(?:y|ies)" 就是一个比 "industry|industries" 更简略的表达式。| |(?=pattern)|非获取匹配,正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)" 能匹配 Windows2000 中的 Windows,但不能匹配 Windows3.1 中的Windows。 预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。| |(?!pattern)|非获取匹配, 负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)" 能匹配 Windows3.1 中的 Windows,但不能匹配Windows2000 中的Windows。 预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始| |(?<=pattern)|非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows" 能匹配 2000Windows 中的 Windows,但不能匹配 3.1Windows 中的 Windows。| |(?<!pattern)|非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如 "(?<!95|98|NT|2000)Windows" 能匹配 3.1Windows 中的 Windows,但不能匹配 2000Windows 中的 Windows。| |x|y|匹配 x 或 y。例如,"z|food" 能匹配 z 或 food。"(z|f)ood" 则匹配 zood 或 food。| |[xyz]|字符集合。匹配所包含的任意一个字符。例如,[abc] 可以匹配 plain 中的 a。| |[^xyz]|负值字符集合。匹配未包含的任意字符。例如,[^abc] 可以匹配 plain 中的 p。[a-z]字符范围。匹配指定范围内的任意字符。例如,| |[a-z]| 可以匹配 a 到 z 范围内的任意小写字母字符。[^a-z]负值字符范围。匹配任何不在指定范围内的任意字符。例如,| |[^a-z]| 可以匹配任何不在 a 到 z 范围内的任意字符。| |\\b|匹配一个单词边界,也就是指单词和空格间的位置。例如,er\\b 可以匹配 never 中的 er ,但不能匹配 verb 中的 er。\\b1_ 可以匹配1_23中的1_,但不能匹配21_3中的1_。| |\\B|匹配非单词边界。er\\B 能匹配 verb 中的 er ,但不能匹配never 中的 er。| |\\cx|匹配由x指明的控制字符。例如,\\cM 匹配一个Control-M 或 回车符。x 的值必须为A-Z或a-z之一。否则,将c视为一个原义的c字符。| |\\d|匹配一个数字字符。等价于 [0-9]。| |\\D|匹配一个非数字字符。等价于[^0-9]。| |\\f|匹配一个换页符。等价于\\x0c和\\cL。| |\\n|匹配一个换行符。等价于\\x0a和\\cJ。| |\\r|匹配一个回车符。等价于\\x0d和\\cM。| |\\s|匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\\f\\n\\r\\t\\v]。| |\\S|匹配任何非空白字符。等价于[^\\f\\n\\r\\t\\v]。| |\\t|匹配一个制表符。等价于\\x09和\\cI。| |\\v|匹配一个垂直制表符。等价于\\x0b和\\cK。| |\\w|匹配包括下划线的任何单词字符。类似但不等价于[A-Za-z0-9_],这里的单词字符使用Unicode字符集。| |\\W|匹配任何非单词字符。等价于[^A-Za-z0-9_]。| |\\xn|匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,\\x41匹配A。\\x041则等价于\\x04&1。正則表达式中可以使用ASCII编码。| |\\num|匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,(.)\\1匹配两个连续的相同字符。| |\\n|标识一个八进制转义值或一个向后引用。如果\\n之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字(0-7),则 n 为一个八进制转义值。| |\\nm|标识一个八进制转义值或一个向后引用。如果\\nm之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果\\nm 之前至少有 n 个获取,则 n 为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\\nm将匹配八进制转义值nm。| |\\nml|如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。| |\\un|匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\\u00A9 匹配版权符号(©)。| [01]: http://nginx.org/en/docs/http/ngx_http_core_module.html#location "Nginx官方wiki"
Nathan
2025年7月18日 13:29
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码