Kubernetes
一、基础知识
1. 概念和术语
2. Kubernetes特性
3. 集群组件
4. 抽象对象
5. 镜像加速下载
二、安装部署kubeadm
1. 基础环境准备
2. 安装runtime容器(Docker)
3. 安装runtime容器(Contained)
4. Containerd进阶使用
5. 部署kubernets集群
6. 部署calico网络组件
7. 部署NFS文件存储
8. 部署ingress-nginx代理
9. 部署helm包管理工具
10. 部署traefik代理
11. 部署dashboard管理面板(官方)
12. 部署kubesphere管理面板(推荐)
12. 部署metrics监控组件
13. 部署Prometheus监控
14. 部署elk日志收集
15. 部署Harbor私有镜像仓库
16. 部署minIO对象存储
17. 部署jenkins持续集成工具
三、kubectl命令
1. 命令格式
2.node操作常用命令
3. pod常用命令
4.控制器常用命令
5.service常用命令
6.存储常用命令
7.日常命令总结
8. kubectl常用命令
四、资源对象
1. K8S中的资源对象
2. yuml文件
3. Kuberbetes YAML 字段大全
4. 管理Namespace资源
5. 标签与标签选择器
6. Pod资源对象
7. Pod生命周期与探针
8. 资源需求与限制
9. Pod服务质量(优先级)
五、资源控制器
1. Pod控制器
2. ReplicaSet控制器
3. Deployment控制器
4. DaemonSet控制器
5. Job控制器
6. CronJob控制器
7. StatefulSet控制器
8. PDB中断预算
六、Service和Ingress
1. Service资源介绍
2. 服务发现
3. Service(ClusterIP)
4. Service(NodePort)
5. Service(LoadBalancer)
6. Service(ExternalName)
7. 自定义Endpoints
8. HeadlessService
9. Ingress资源
10. nginx-Ingress案例
七、Traefik
1. 知识点梳理
2. 简介
3. 部署与配置
4. 路由(IngressRoute)
5. 中间件(Middleware)
6. 服务(TraefikService)
7. 插件
8. traefikhub
9. 配置发现(Consul)
10. 配置发现(Etcd)
八、存储
1. 配置集合ConfigMap
6. downwardAPI存储卷
3. 临时存储emptyDir
2. 敏感信息Secret
5. 持久存储卷
4. 节点存储hostPath
7. 本地持久化存储localpv
九、rook
1. rook简介
2. ceph
3. rook部署
4. rbd块存储服务
5. cephfs共享文件存储
6. RGW对象存储服务
7. 维护rook存储
十、网络
1. 网络概述
2. 网络类型
3. flannel网络插件
4. 网络策略
5. 网络与策略实例
十一、安全
1. 安全上下文
2. 访问控制
3. 认证
4. 鉴权
5. 准入控制
6. 示例
十二、pod调度
1. 调度器概述
2. label标签调度
3. node亲和调度
4. pod亲和调度
5. 污点和容忍度
6. 固定节点调度
十三、系统扩展
1. 自定义资源类型(CRD)
2. 自定义控制器
十四、资源指标与HPA
1. 资源监控及资源指标
2. 监控组件安装
3. 资源指标及其应用
4. 自动弹性缩放
十五、helm
1. helm基础
2. helm安装
3. helm常用命令
4. HelmCharts
5. 自定义Charts
6. helm导出yaml文件
十六、k8s高可用部署
1. kubeadm高可用部署
2. 离线二进制部署k8s
3. 其他高可用部署方式
十七、日常维护
1. 修改节点pod个数上限
2. 集群证书过期更换
3. 更改证书有效期
4. k8s版本升级
5. 添加work节点
6. master节点启用pod调度
7. 集群以外节点控制k8s集群
8. 删除本地集群
9. 日常错误排查
10. 节点维护状态
11. kustomize多环境管理
12. ETCD节点故障修复
13. 集群hosts记录
14. 利用Velero对K8S集群备份还原与迁移
15. 解决K8s Namespace无法正常删除的问题
16. 删除含指定名称的所有资源
十八、k8s考题
1. 准备工作
2. 故障排除
3. 工作负载和调度
4. 服务和网络
5. 存储
6. 集群架构、安装和配置
本文档使用 MrDoc 发布
-
+
首页
6. 集群架构、安装和配置
# 访问控制(RBAC) ## 参考文档 [https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/rbac/](https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/rbac/) ## 例题 创建一个名为deployment-clusterrole且仅允许创建以下资源类型的新ClusterRole:<br />Deployment<br />StatefulSet<br />DaemonSet<br />在现有的 namespace app-team1中创建一个名为cicd-token的新 ServiceAccount。<br />限于 namespace app-team1中,将新的ClusterRole deployment-clusterrole绑定到新的 ServiceAccount cicd-token。 ## 解题思路 RBAC基本概念 - Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。 - Subject:被作用者,既可以是“人”,也可以是“机器”,也可以使你在 Kubernetes 里定义的“用户”。 - RoleBinding:定义了“被作用者”和“角色”的绑定关系。 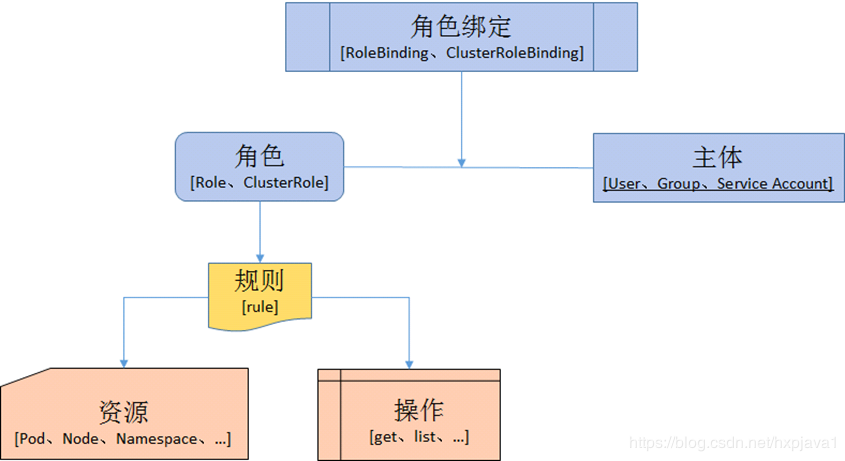<br />解题步骤 - 创建ClusterRole,并指定操作权限操作资源以及名称 - 创建ServiceAccount,指定名称和名称空间 - 创建ClusterRoleBinding ,将ServiceAccount和ClusterRole绑定 - 验证权限 ## 答案 使用yaml文件创建 ```yaml apiVersion: v1 kind: ServiceAccount metadata: name: cicd-token namespace: app-team1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: deployment-clusterrole rules: - apiGroups: [""] resources: ["deployment", "statefulset", "daemonset"] verbs: ["create"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: deployment-rolebinding namespace: app-team1 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: deployment-clusterrole subjects: - kind: ServiceAccount name: cicd-token namespace: app-team1 ``` 使用命令行创建 ```yaml # 创建clusterrole [root@k8s-master ~]# kubectl create clusterrole deployment-clusterrole --verb=create --resource=deployment,statefulset,daemonset clusterrole.rbac.authorization.k8s.io/deployment-clusterrole created # 创建serviceaccount [root@k8s-master ~]# kubectl create serviceaccount cicd-token -n app-team1 serviceaccount/cicd-token created # 创建rolebinding [root@k8s-master ~]# kubectl create rolebinding cicd-token-rolebinding --serviceaccount=app-team1:cicd-token --clusterrole=deployment-clusterrole -n app-team1 rolebinding.rbac.authorization.k8s.io/cicd-token-rolebinding created ``` 测试权限 ```yaml [root@k8s-master ~]# kubectl --as=system:serviceaccount:app-team1:cicd-token get pods -n app-team1 Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:app-team1:cicd-token" cannot list resource "pods" in API group "" in the namespace "app-team1" ``` ## 答案 ```yaml # 将节点停止调度 [root@k8s-master ~]# kubectl cordon k8s-work2 # 驱逐节点 [root@k8s-master ~]# kubectl drain k8s-work2 node/k8s-work2 cordoned error: unable to drain node "k8s-work2" due to error:[cannot delete Pods declare no controller (use --force to override): default/test, cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-flannel/kube-flannel-ds-dq27j, kube-system/kube-proxy-dl77v], continuing command... There are pending nodes to be drained: k8s-work2 cannot delete Pods declare no controller (use --force to override): default/test cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-flannel/kube-flannel-ds-dq27j, kube-system/kube-proxy-dl77v # 根据提示添加选项 [root@k8s-master ~]# kubectl drain ek8s-node-1 --force --ignore-daemonsets ``` # 升级k8s版本 ## 参考文档 [https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/](https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/) ## 例题 现有的kubernetes集群正在运行版本:1.24.13。仅将主节点上(k8s-master)的所有kubernetes控制平面和节点组件升级到版本1.24.14<br />确保在升级之前drain主节点,并在升级后uncordon主节点。<br />另外,在主节点上升级kubelet和kubectl ## 解题思路 升级工作的基本流程如下: 1. 升级主控制平面节点 2. 升级其他控制平面节点 3. 升级工作节点 节点升级基本步骤如下: 1. 将节点设置为不可用 2. 安装指定版本的kubeadm 3. 执行upgrade命令查看升级计划 4. 执行upgrade升级k8s组件 5. 升级kubelet和kubectl 6. 重启kubelet 7. 将节点设置为可调度 8. 查看升级结果 ## 答案 ```bash # 将节点设置为不可用 [root@k8s-master ~]# kubectl drain k8s-master node/k8s-master cordoned error: unable to drain node "k8s-master" due to error:cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-flannel/kube-flannel-ds-45rxr, kube-system/kube-proxy-fl2cq, continuing command... There are pending nodes to be drained: k8s-master cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-flannel/kube-flannel-ds-45rxr, kube-system/kube-proxy-fl2cq [root@k8s-master ~]# kubectl drain k8s-master --ignore-daemonsets # 安装指定版本的kubeadm # 实际考试中需要sudo -i,然后执行apt install kubeadm=1.24.14-00 [root@k8s-master ~]# dnf -y install kubeadm-1.24.14 # 查看升级计划 [root@k8s-master ~]# kubeadm upgrade plan Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply': COMPONENT CURRENT TARGET kubelet 3 x v1.24.13 v1.24.14 Upgrade to the latest version in the v1.24 series: COMPONENT CURRENT TARGET kube-apiserver v1.24.13 v1.24.14 kube-controller-manager v1.24.13 v1.24.14 kube-scheduler v1.24.13 v1.24.14 kube-proxy v1.24.13 v1.24.14 CoreDNS v1.8.6 v1.8.6 etcd 3.5.6-0 3.5.6-0 You can now apply the upgrade by executing the following command: kubeadm upgrade apply v1.24.14 # 执行升级操作,可以指定哪些组件不需要升级,例如etcd [root@k8s-master ~]# kubeadm upgrade apply v1.24.14 --etcd-upgrade=false [upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.24.14". Enjoy! [upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven\'t already done so. # 升级kubelet和kubectl [root@k8s-master ~]# dnf -y install kubelet-1.24.14 kubectl-1.24.14 # 重启kubelet [root@k8s-master ~]# systemctl restart kubelet [root@k8s-master ~]# systemctl status kubelet # 设置节点为可调度 [root@k8s-master ~]# kubectl uncordon k8s-master node/k8s-master uncordoned # 验证升级结果 [root@k8s-master ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master Ready control-plane 4d21h v1.24.14 k8s-work1 Ready <none> 4d21h v1.24.13 k8s-work2 Ready <none> 4d21h v1.24.13 ``` # etcd备份与恢复 ## 参考文档 [https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/configure-upgrade-etcd/](https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/configure-upgrade-etcd/) ## 例题 为运行在https://127.0.0.1:2379上的现有etcd实例创建快照并将快照保存到/data/backup/etcd-snapshot.db<br />然后还原位于/data/backup/etcd-snapshot-previous.db的现有先前快照 > 提供了以下TLS证书和密钥,以通过etcdctl连接到服务器 > CA证书:/etc/etcd/pki/ca.pem > 客户端证书:/etc/etcd/pki/client.pem > 客户端密钥:/etc/etcd/pki/client-key.pem ## 解题思路 执行备份和恢复命令时,一定要指定etcdctl_api版本为3,否则报错。<br />在恢复etcd数据时,先停止etcd服务,然后查看数据目录和用户组,然后将原来的数据移走,最后再恢复数据启动服务。 ## 答案 ```bash # 备份 [root@k8s-master ~]# ETCDCTL_API=3 etcdctl snapshot save /data/backup/etcd-snapshot.db --endpoints=https://127.0.0.1:2379 --cacert=/etc/etcd/pki/ca.pem --cert=/etc/etcd/pki/client.pem --key=/etc/etcd/pki/client-key.pem {"level":"info","ts":"2023-05-16T10:56:39.347+0800","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/data/backup/etcd-snapshot.db.part"} {"level":"info","ts":"2023-05-16T10:56:39.496+0800","logger":"client","caller":"v3@v3.5.6/maintenance.go:212","msg":"opened snapshot stream; downloading"} {"level":"info","ts":"2023-05-16T10:56:39.497+0800","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"https://127.0.0.1:2379"} {"level":"info","ts":"2023-05-16T10:56:40.384+0800","logger":"client","caller":"v3@v3.5.6/maintenance.go:220","msg":"completed snapshot read; closing"} {"level":"info","ts":"2023-05-16T10:56:40.449+0800","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"https://127.0.0.1:2379","size":"5.1 MB","took":"1 second ago"} {"level":"info","ts":"2023-05-16T10:56:40.449+0800","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/data/backup/etcd-snapshot.db"} Snapshot saved at /data/backup/etcd-snapshot.db [root@k8s-master ~]# ls -lh /data/backup/etcd-snapshot.db -rw------- 1 root root 4.9M 5月 16 10:56 /data/backup/etcd-snapshot.db # 恢复 [root@k8s-work1 ~]# systemctl stop etcd [root@k8s-work1 ~]# systemctl cat etcd # 确认下数据目录(--data-dir值) [root@k8s-work1 ~]# mv /var/lib/etcd /var/lib/etcd.bak [root@k8s-work1 ~]# ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/etcd/pki/ca.pem --cert=/etc/etcd/pki/client.pem --key=/etc/etcd/pki/client-key.pem snapshot restore --data-dir=/var/lib/etcd /data/backup/etcd-snapshot-previous.db {"level":"info","ts":1684658606.325091,"caller":"snapshot/v3_snapshot.go:296","msg":"restoring snapshot","path":"/data/backup/etcd-snapshot-previous.db","wal-dir":"/var/lib/etcd/member/wal","data-dir":"/var/lib/etcd","snap-dir":"/var/lib/etcd/member/snap"} {"level":"info","ts":1684658606.4937744,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"cdf818194e3a8c32","local-member-id":"0","added-peer-id":"8e9e05c52164694d","added-peer-peer-urls":["http://localhost:2380"]} {"level":"info","ts":1684658606.5958042,"caller":"snapshot/v3_snapshot.go:309","msg":"restored snapshot","path":"/data/backup/etcd-snapshot-previous.db","wal-dir":"/var/lib/etcd/member/wal","data-dir":"/var/lib/etcd","snap-dir":"/var/lib/etcd/member/snap"} # 考试是所属组可能不一致,记得调整 [root@k8s-work1 ~]# chown -R etcd:etcd /var/lib/etcd [root@k8s-work1 ~]# systemctl start etcd ``` # 设置节点不可用 ## 参考文档 [https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/safely-drain-node/](https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/safely-drain-node/) ## 例题 将名为k8s-work2的node设置为不可用,并重新调度该node上所有运行的pods ## 解题思路 在对节点执行维护(例如内核升级、硬件维护等)之前, 可以先使用kubectl cordon命令,将节点停止调度,然后执行kubectl drain 从节点安全地逐出所有 Pod。<br />如果执行drain提示错误,根据提示再加上选项,例如--delete-local-data --force <br />drain的参数 - –force:当一些pod不是经 ReplicationController, ReplicaSet, Job, DaemonSet 或者 StatefulSet 管理的时候就需要用–force来强制执行 (例如:kube-proxy) - –ignore-daemonsets:无视DaemonSet管理下的Pod - –delete-local-data:如果有mount local volumn的pod,会强制杀掉该pod并把料清除掉 ## 答案 ```bash [root@k8s-master ~]# kubectl cordon k8s-work2 node/k8s-work2 cordoned [root@k8s-master ~]# kubectl drain k8s-work2 node/k8s-work2 already cordoned error: unable to drain node "k8s-work2" due to error:[cannot delete Pods declare no controller (use --force to override): default/filebeat, default/kucc4, default/web-server, cannot delete Pods with local storage (use --delete-emptydir-data to override): default/legacy-app, cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-flannel/kube-flannel-ds-dq27j, kube-system/kube-proxy-4xbgn], continuing command... There are pending nodes to be drained: k8s-work2 cannot delete Pods declare no controller (use --force to override): default/filebeat, default/kucc4, default/web-server cannot delete Pods with local storage (use --delete-emptydir-data to override): default/legacy-app cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-flannel/kube-flannel-ds-dq27j, kube-system/kube-proxy-4xbgn [root@k8s-master ~]# kubectl drain k8s-work2 --force --delete-emptydir-data --ignore-daemonsets ```
Nathan
2024年6月22日 12:48
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文件
Docx文件
分享
链接
类型
密码
更新密码